Instapaper’s backup method
I mentioned earlier on Twitter that my home computer downloaded a 22 GB database dump every three days as part of Instapaper’s backup method, and a lot of people expressed interest in knowing the full setup.
The code and database are backed up separately. The code is part of my regular document backup which uses a combination of Time Machine, SuperDuper, burned optical discs, and Backblaze.
The database backup is based significantly on MySQL replication. For those who aren’t familiar, it works roughly like this:
- The “master” database is configured to write a binary log (“binlog”) of every change it makes to the data.
- A snapshot of the entire database is taken, noting the current position in the binlog, and copied to the “slave” server.
- The slave server can then start itself up with that snapshot, knowing what binlog position it needs to start from, and continuously stream the binlog data from the master, replicating every change that the master makes, to keep itself up to date.
And the binlogs can be decoded, edited, or replayed against the database however you like. This is incredibly powerful: given a snapshot and every binlog file since it was taken, you can recreate the database as it was at any point in time, or after any query, between the time it was taken and the time your binlogs end.
Suppose your last backup was at binlog position 259. Someone accidentally issued a destructive command, like an unintentional DELETE or UPDATE without a WHERE clause on a big table, at binlog position 1000. The database is now at position 1200 (and you don’t want to lose the changes since the bad query). You can:
- Instantiate the backup (at its binlog position 259)
- Replay the binlog from position 260 through 999
- Replay the binlog from position 1001 through 1200
And you’ll have a copy of the complete database if that destructive query had never happened.
Replication is particularly useful for backups, because you can just stop MySQL on a slave, copy its data directory somewhere, and start MySQL again. The directory is then a perfect snapshot with binlog information (in the master.info file). If you can’t afford the slave’s downtime, or you want to snapshot a running master without locking writes, you can use mysqldump if the database is small or xtrabackup if it’s big, but it’s really best to dedicate a slave to backups if you can.
So here’s how I use replication for Instapaper’s backups: (click for larger version)
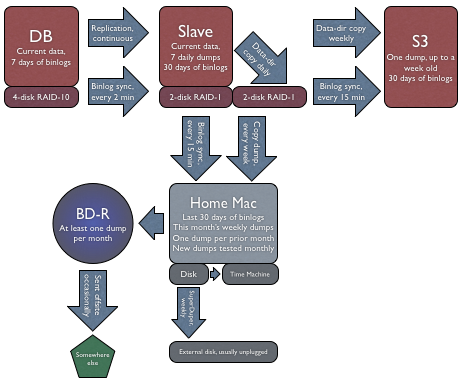
UPDATED, one day later: Inspired by the emails I’ve gotten in response, I’ve accelerated my S3 plans and did it all today. Now featuring automatic S3 backups as well. I’ve updated the diagram and description to include this.
The slave takes snapshots (“dumps”) of its data directory every day and continuously copies the binlogs from the master to its own disks and to my home computer with rsync. Once a week, it copies that day’s entire data dump to Amazon S3 and my home computer.
The dumps have the binlog name and position conveniently in their filenames:
instapaper-2010-11-01-binlog.018268-pos684048.tar.gz
These are additionally backed up from my home computer with Time Machine and SuperDuper. Additionally, I occasionally burn a Blu-ray disc with the most recent dump, and I take some of them offsite.
The slave is usually within 1 second of being up to date. And since the binlogs are synced every few minutes, the copies on my home computer and S3 are almost always within 15 minutes of being current.
Room for improvement
Of course, there’s always room for improvement in a backup scheme:
- If I store more binlogs, I could get away with less-frequent dumps sent to my home computer. (As the data size grows, I’ll need to do this.)
- My offsite transfers should be more frequent.
- The backups should be tested automatically, in addition to the monthly manual testing that I perform now.
And you can probably think of an improvement that I haven’t considered. If so, please email me. Thanks.