Introducing Voice Boost 2: Remaster your podcasts
The latest update to Overcast includes a feature that I’m especially proud of that took over a year to build.
Voice Boost 2 is an all-new audio engine that includes professional-grade, mastering-quality loudness normalization.
When I first introduced Overcast in 2014, Voice Boost was one of its headlining features:
Voice Boost is a combination of dynamic compression and equalization that can make many shows more listenable and normalize volume across all shows. This makes amateur-produced podcasts (including many of my favorites) more listenable in loud environments, like cars, where you’d otherwise need to crank the volume so loudly to hear the quiet parts that you’d blow your ears out when the loudest person spoke.
Voice Boost 2 achieves the same goal as the original Voice Boost, but with dramatically more sophisticated methods, leading to more consistent results and much better sound quality.
Goals
When I wrote the original Voice Boost with only a rudimentary understanding of audio processing, it was a single configuration of Apple’s AudioUnits that applied a fixed set of parameters to all podcasts, regardless of their audio characteristics. It was an effective but blunt tool, relying on aggressive level compression and a strong EQ to make the compression less noticeable.
Since then, I’ve edited over 500 podcasts, learned a lot more about how to master them properly, and developed a much better understanding of audio signal processing.
I set out to develop a better, smarter, and more refined Voice Boost that took advantage of everything I’d learned, with these audio goals:
- The effect should be much more subtle: mostly just consistent volume, plus slightly smoother tone.
- It should analyze the input audio and apply just enough processing to achieve a consistent volume level, modifying already-good audio as little as possible.
- It should sound good, and consistent, regardless of the volume dynamics of its input.
- Quality should be so good that I can even play high-quality music through it1 and not notice any artifacts.
And these technical goals:
- Like Smart Speed and the original Voice Boost, it had to work as a streaming process, easily toggled on and off at will, without needing to scan the entire file first or look very far ahead.
- The code had to be pure C, with highly optimized and vectorized code, so it wouldn’t be a major power drain on older phones and could potentially run on much lower-power devices as well.
- I had to write every component from scratch, without using AudioUnits, because I wanted to understand and control everything, ensure the highest performance and sound quality, and avoid Apple’s platform-specific API limits.2
- It had to be modular and easily customizable, like a channel strip in an audio editor, so I could adjust the processing during development and testing, offer user customization down the road, and use the same engine to build myself a modular podcast-preproduction tool to save time in my weekly workflow (which I’ve been using for over a year).3
Live LUFS normalization
Since Voice Boost is mostly about high-quality volume analysis and loudness normalization, I went straight to the top, implementing the ITU BS.1770–4 standard that gives us the LUFS measurement seen in high-end audio editors.
Overcast now measures and adjusts podcast levels using this broadcast-standard perceptual loudness algorithm, at full quality, with no preprocessing.
Voice Boost 2 normalizes all podcasts to –14 LUFS — a level I chose because it closely matches the volume of Siri and most iOS turn-by-turn navigation voices, so when you’re listening to a podcast while driving, navigation interruptions are less jarring.
Most professionally produced podcasts are already mastered to similar volume levels, so Voice Boost 2 won’t overcompress them with aggressive processing — it’ll only apply as much correction as necessary to make them all the same volume.
A brief tutorial on clipping and distortion
This is about to get nerdier, but bear with me. (Yes, nerdier than ITU broadcast-loudness standards.)
Given a loudness measurement for the incoming audio, quieter podcasts need to be amplified to reach the target. But perceived loudness isn’t the peak of the incoming audio stream — it’s more of an average. Quiet-sounding audio can still have brief moments of loud peaks.
When increasing the volume of digital audio, the biggest challenge is not “clipping” during the peaks — not having any part of the signal pass above the volume ceiling of 0 dB. (It’s a negative scale. This is also why the LUFS value above, which is closely related to the decibel scale used here, is negative.)
Here’s the highest the signal should go, showing the individual audio samples (green dots) that can be processed by a podcast app before the DAC transforms them into audio (smooth green line):
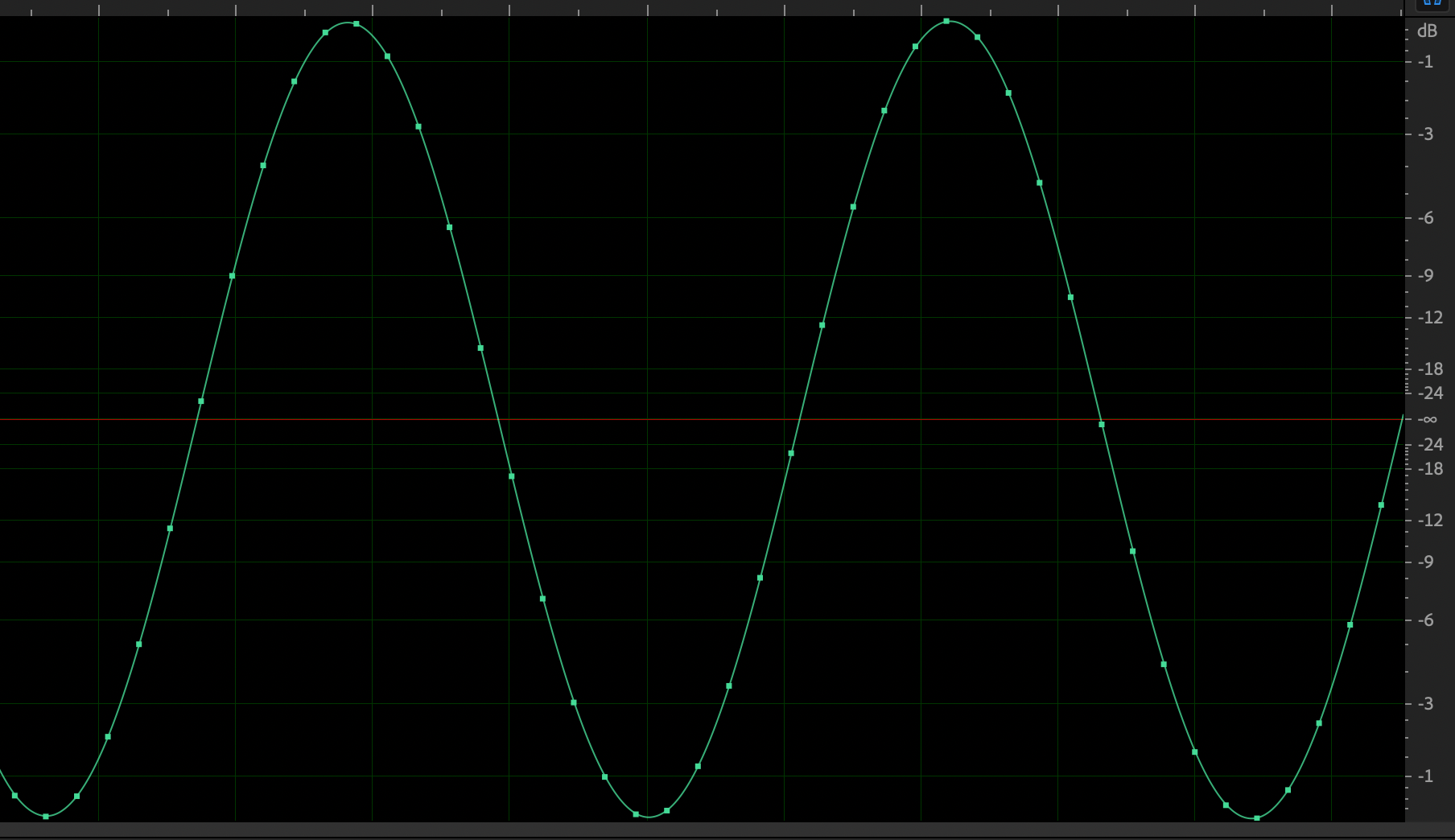
It’ll sound right as long as the audio doesn’t cross above that top line (0 dB). Increase the volume even slightly too far, and some of the samples just slam into it and stay there, losing the tops of their smooth curves:
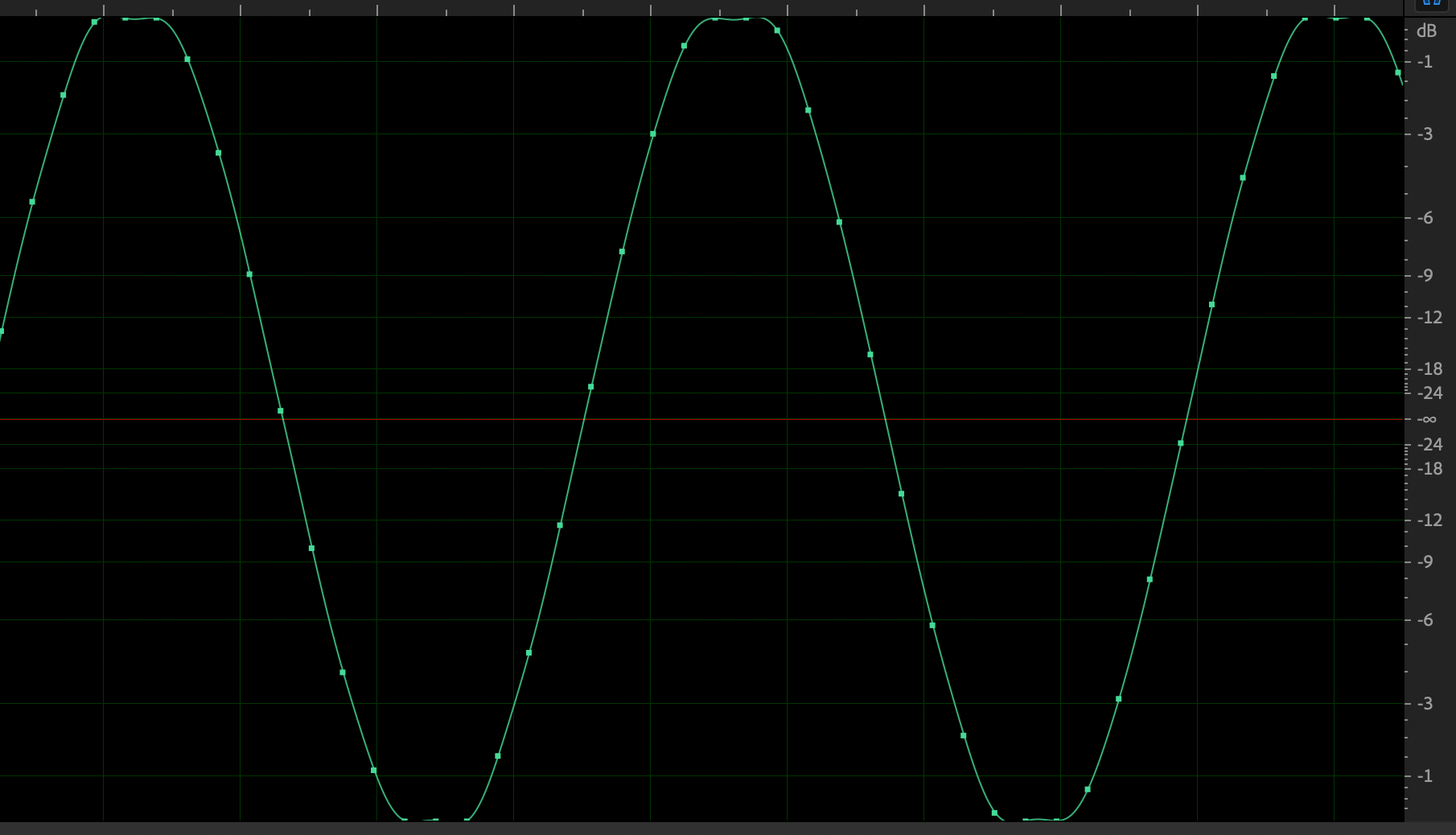
And that sounds terrible.
But I can’t just cap all the samples right below the limit and call it a day — that’s called a brickwall limiter — because then the shape of the audio line will actually represent different frequencies, telling the DAC to add noise that wasn’t really there.
Here, the bottom of each image shows the frequency breakdown:
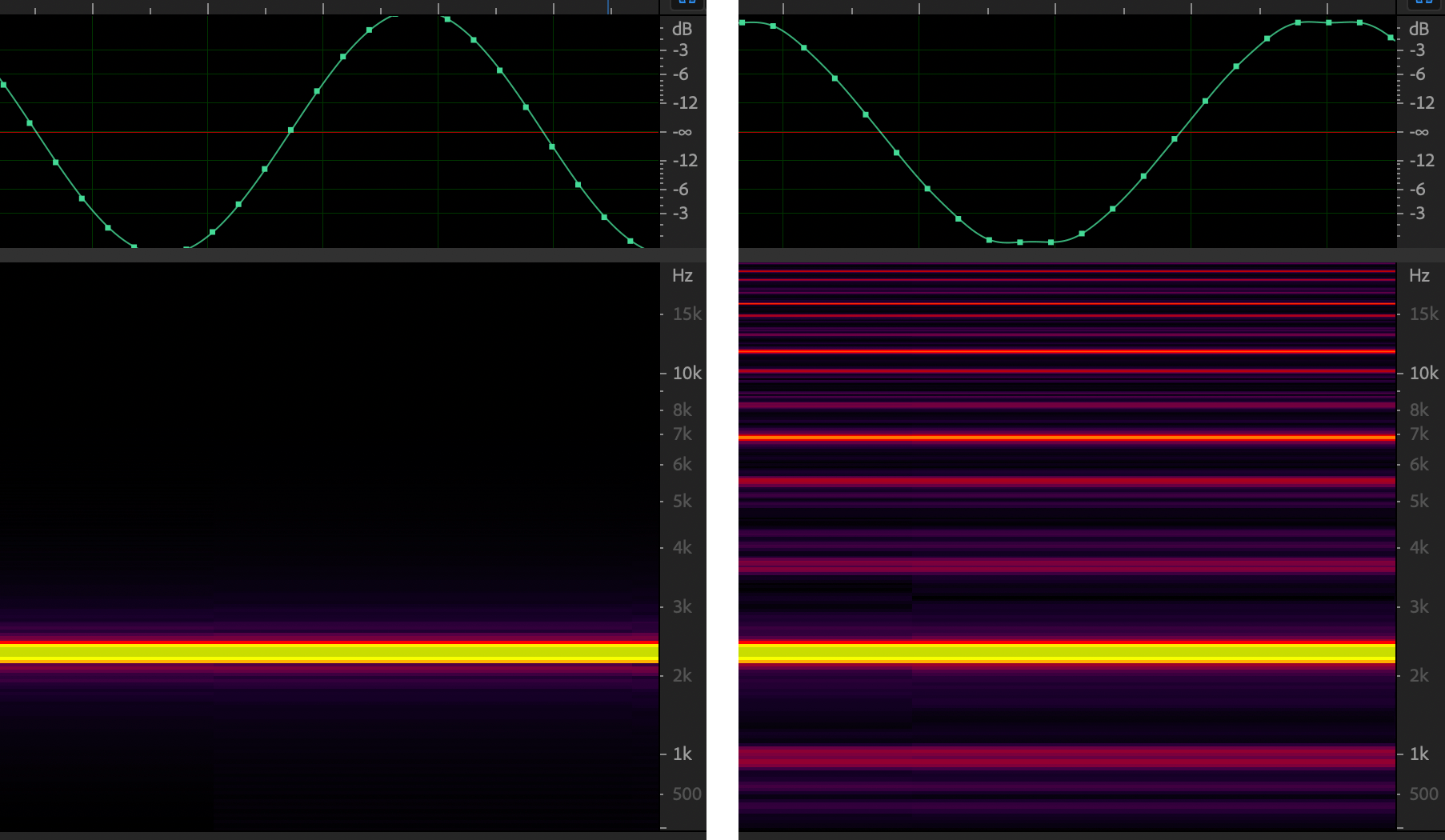
The unclipped signal (left) shows only its original frequency of about 2100 Hz, but a basic brickwall limiter (right) results in the unwanted introduction of a bunch of extra frequencies.
That’s distortion. (If this is interesting to you, learn more about audio sampling theory here.)
Lookahead limiter
Avoiding audible distortion requires a lookahead limiter, which looks… ahead (😎) at the audio coming down the pipeline, and smoothly ramps the volume amplification down as a loud peak is approaching, then back up again afterward, just enough to avoid clipping and audible distortion, but so quickly that you don’t notice.4
After Voice Boost 2’s complete 32-bit audio processing pipeline, the last stage is a lookahead limiter, configured such that it can’t clip, no matter what audio comes through.
This gives vast flexibility in volume processing without sacrificing quality.
Voice Boost 2 also incorporates a dynamics compressor, but over time, I’ve kept reducing its strength as I’ve found it less necessary. Proper LUFS processing with a great lookahead limiter provides excellent volume normalization with almost no compression needed afterward.
True-peak detection
There’s one more way to introduce clipping that needs to be guarded against.
Digital audio is represented by samples that represent a point in time (green dots, again) on a sound wave (green line). But the sampled points don’t always land at the exact peaks of those waves:
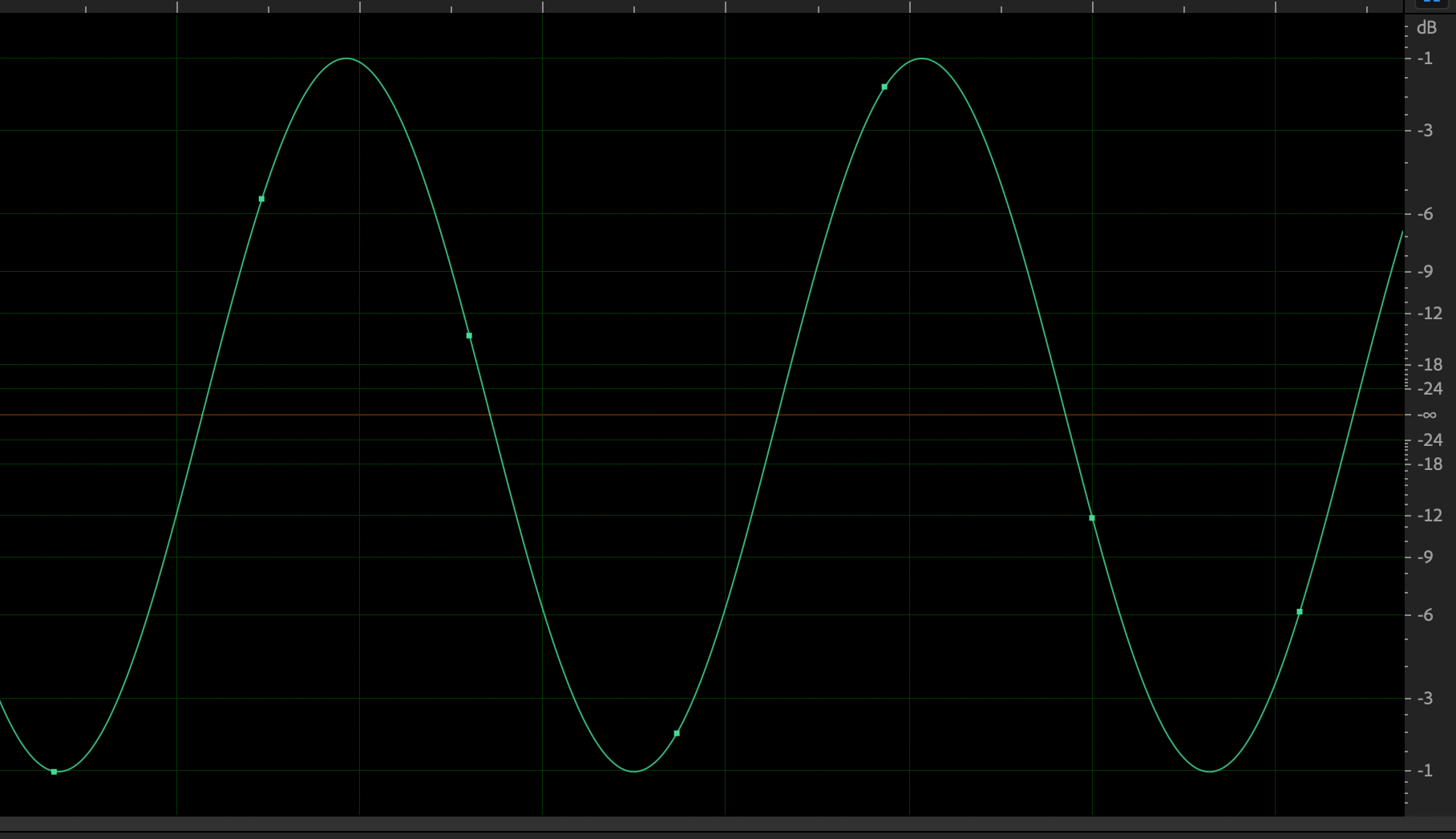
The most common way to measure the peak of a waveform is to find the greatest absolute sample value. By this method, the top waveform peaks here would measure about –6 dB and –1.5 dB, respectively.
But the actual peak amplitudes of these waves is –1 dB! A simple limiter could still output clipped audio because it’s not seeing the true peaks.
Voice Boost 2’s limiter performs true-peak detection, rather than simply measuring sample peaks, to avoid this type of clipping and further reduce distortion.
Mastering-quality processing for everyone
Voice Boost 2 is a mastering-quality audio-processing pipeline that applies broadcast-standard loudness normalization, light compression and EQ, and a true-peak lookahead limiter to your podcasts, in real time, without sacrificing quality or battery life.
And it runs at less than 1% CPU usage on an iPhone SE.5
I intend to expose some of its customizability to customers in future updates, but I wanted to develop and ship the best default settings first to keep the app simple and usable to everyone. Now that it’s available to everyone, I may still subtly tweak the defaults in response to feedback. But as I’ve refined the settings during the beta period to be more universal, less customization has been necessary.6
Having achieved its goals of being more consistent and less aggressive, Voice Boost 2 is intentionally transparent. It’s not promoted more in the app or even labeled “Voice Boost 2”. It’s still Voice Boost — just better now.
If I did my job well, you’ll hardly notice it at all. You’ll have no idea that your podcasts are being remastered in your pocket.
But I’ll know. And the handful of you who really care will know. And that’s enough for me.
Voice Boost 2 is in today’s update (2020.1), along with these new features:
- AirPlay 2: Overcast can now play to HomePods and other AirPlay 2 devices much more responsively, with full-blown Smart Speed and Voice Boost, on iOS 13.1 and above.7
- Skip intros/outros: There’s a new per-podcast setting to skip a given number of seconds from the start and/or end of its episodes.
- Clip-sharing from private feeds. In retrospect, this restriction was unnecessary, so I lifted it.
- Restored iOS 12 compatibility. Going 13-only so soon was a mistake. Hear why on Under The Radar 181 and 183.
As usual, all of this is free for everyone in Overcast.
-
Those awesome Trey Anastasio acoustic shows are pretty quiet. ↩︎
-
Apple doesn’t make all of their audio APIs available on all platforms: some are Mac-only and never came to iOS, and watchOS has an even smaller subset than iOS. The more I can accomplish in my own code, the less I depend on Apple’s choices for which APIs they make available to developers. ↩︎
-
It’s just a command-line tool for now. You don’t want it. (But if you do… someday, maybe.) ↩︎
-
This all happens in milliseconds. ↩︎
-
At 1X, with Smart Speed enabled.
Smart Speed was actually entirely rewritten as part of Voice Boost 2, but it’s less interesting. It performs the same job as before, but much more efficiently, and taking advantage of the measured loudness when Voice Boost is also enabled. ↩︎
-
For instance, I also built a de-esser into Voice Boost 2, but it slowly became unnecessary as I improved the other processing, so it’s not currently enabled. ↩︎
-
Smart Speed is a big deal here, I think — I’m not aware of any other podcast apps with silence-skipping over AirPlay 2.
(Or LUFS normalization, or true-peak lookahead limiters.) ↩︎