For Mac OS reviews, read John Siracusa. For Mac reviews, read Anand.
I got much more than I expected from what’s ostensibly a review of a new workstation. Page 2 is particularly interesting for the future of CPU performance even if you have no interest in the Mac Pro.
I wish the benchmarks also included results from the 8-core, though — Anand’s 12-core review unit suffers more against the much faster single-threaded performance of the iMac and 15” Retina MacBook Pro. Macworld’s 8-core tests show that while the iMac sometimes beats the Mac Pro, it’s less often and with a smaller gap than with Anand’s slower-clocked 12-core.
Regardless, Anand’s tests confirm that the new Mac Pro can be a huge win, but only for software written to take advantage of heavy CPU parallelism or OpenCL. For everything else, it’s great, but probably not worth its price difference over an iMac or RMBP for most buyers.
That said, we’ve had many laptops, a few Mac Pros, and even an iMac in our household over the years, and while I have regretted the iMac and some laptops over their lifespans, I’ve never regretted the Mac Pros.
And I’m glad that a new physical design and including dual GPUs standard has transformed Apple’s most ignored, stagnant, endangered Mac into something cool and worthy of press attention again.1 I never thought the Mac Pro would regain any share of the spotlight, but I’m glad to be proven wrong.
Apple could have just retained the old case design, updated to Xeon E5 CPUs, and made dual GPUs the new baseline configuration, and nobody would have cared (except me, Anand, and John Siracusa). They’d still have PCIe slots, drive bays, and a lot more fans. Dual sockets could add huge ceiling-performance gains for those willing to pay a lot for a pair of 8-core E5-2667 v2s (16 cores with no single-threaded penalty) or 12-core E5-2697 v2s (slower cores, but 24 of them!).
But then it would still be huge, ugly, boring, dated, louder, and more power-hungry. Thunderbolt as a display output/expansion combo would have still been a problem to implement. And all of those card slots and options would have prevented Apple from optimizing the PCIe layout.
I was doubtful when they first announced it last summer, but I think they made the right choices. ↩︎
Great article at The Atlantic by David H. Freedman:
Again and again, carefully controlled studies have shown alternative medicine to work no better than a placebo. But now many doctors admit that alternative medicine often seems to do a better job of making patients well, and at a much lower cost, than mainstream care—and they’re trying to learn from it.
I saw a lot of “alternative” “medicine” in my teenage years, and it was all complete bullshit. But it has always worked for other people in my family to alleviate minor ailments or pain because they believe in it. It drives me nuts that they blow money on scams and quackery, but it solves their problems, so it’s hard to argue with them.1
Freedman does a great job of explaining the complicated issue: alternative medicine is complete bullshit, but it actually does work for many common health problems due to the incredible power of the placebo effect — often more effectively than real medicine, which is much less effective than many of us assume.
The interesting dilemma is whether it’s possible to integrate some voodoo bullshit into real medical care to significantly improve overall health with no negative side effects, such as people eschewing real care when it’s really necessary, blowing more money than they can afford on fake treatments, or being injured by practices or products that aren’t held to any standards or testing.
The answer isn’t clear-cut, especially since “real” medicine also doesn’t have a very good track record of avoiding unnecessary drugs and surgeries, keeping patient costs low, and minimizing negative side effects through rigorous testing and consistently high standards.
The same applies to a lot of expensive wine and audio equipment. ↩︎
This isn’t about news or Apple rumors — it’s mostly long, detailed explanations of how various parts of electronics work, how products are manufactured, and what trade-offs must be made. And unlike me, John Chidgey actually knows what he’s talking about.
Start at the beginning. I’ve learned a ton from each episode.
Peter Cohen’s argument is compelling: while written reviews provide important value to shoppers, the far more numerous 1- to 5-star ratings are to blame for most problems with App Store customer reviews:
I say this as someone who’s reviewed software for nigh on 20 years now — reviews of any type are entirely subjective, and whittling them down to a facile up- or down-vote or numerical rating system ultimately demeans the efforts of the developers that create these apps. If I didn’t like an app’s design, should I remove one star or just half a star? What if it crashes? Is that an instant one-star rating? How many stars do I take off for grammar or punctuation errors?
5-star rating systems have always been ineffective and dysfunctional because people have such different and inconsistent standards on what deserves each rating.
Eliminating the star ratings but leaving the written reviews would eliminate a lot of developer headaches and much of the motivation behind the annoying “Rate This App” epidemic that’s interrupting and annoying iOS customers and infecting, embarrassing, and devaluing almost all modern iOS apps.
I hope Apple’s listening. Their culture values quality, but many conditions, abuses, and dysfunctions in the App Store just keep getting worse — and that’s only going to lead to worse apps, more abandoned apps, and more customers who struggle to see a difference between the iOS and Android app ecosystems.
Is there a Facebook update that compares to building a thing? No, but I’d argue that 82 Facebook updates, 312 tweets, and all those delicious Instagram updates are giving you the same chemical impression that you’ve accomplished something of value. Whether it’s all the consumption or the sense of feeling busy, these micro-highs will never equal the high when you’ve actually built.
Look at that nice font on his site, too.
Spending time on social media and fluffy web browsing feels a lot like eating junk food to me. It feels great in short bursts, but too much of it just leaves me tired with a stomachache.
After many writers (myself included) exploded with rage at Information Architects’ patent threats over part-of-speech highlighting, iA announced that they will “drop” their pending patents.
I retweeted their update, but didn’t update the post. Few others did, and Collin Donnell’s calling us out:
If a company does something you don’t like, you speak out, and they correct it, that means what you did worked. It means you got what you wanted. Isn’t the right thing to acknowledge them for it?
Multiple actions by iA angered me:
For a software-feature idea they had, they thought they deserved exclusivity, or royalties from anyone doing something similar (whether accidental or not), for 20 years1 — at a time when small software developers (like iA) are under constant attacks from patent threats and extortion over unintentional infringement of software patents.
They began the process of attempting to secure those restrictions.
They immediately began threatening other developers against developing similar features.
Canceling the patent filings only really absolved them of number 2: the fact that they even did numbers 1 and 3 still angers and offends me. Filing a patent application was an action that they undid, but thinking they deserved one in the first place and threatening other developers (prematurely, at that) are offensive to me in ways that are harder to just cancel and sweep under the rug.
I was silent about their update because it didn’t change anything for me.
Many have criticized the feature they attempted to patent because it’s just using the linguistic-tagger API available in Cocoa for years, but I don’t think that’s relevant.
It doesn’t matter how much time you put into your idea (or didn’t) — I don’t think ideas are exclusive property. Copyright and trademark protection make sense in practice overall, but patents don’t. The idea of “protecting inventors” is a charming fairy tale, but it conflicts with how invention really works (wow) and is a huge burden on our industry. ↩︎
If you’re using deep links for your app, you know two things about them: deep links give users a better experience when they already have your app, and a worse one when they don’t.
Now you can fix this busted UX. Tapstream’s Deferred Deep Linking lets you deep-link all of your users, including ones that don’t yet have your app.
Using Tapstream’s attribution engine, Deferred Deep Linking stores the user’s intended in-app destination before sending them to the App Store. When they run the app for the first time, Deferred Deep Linking recognizes the user and redirects them to the intended deep link.
Participation in this beta is free for approved iOS and Android apps.
Three major factors have probably prevented a proper 2×-in-each-dimension “Retina” version of today’s 27″ iMac and standalone Thunderbolt Display, which would need to be 5120×2880 pixels:
Nobody makes general-purpose LCD panels with that resolution today. “4K” panels are 3840×2160, but 5120×2880 is about 1.8 times the pixel count — a substantial increase. It’s the (exact) same ratio as the difference between the first 24″ (1920×1200) and 30″ (2560×1600) panels. Since 4K panels are just starting to become mass-produced and affordable to high-end computer buyers, available and affordable 5120×2880 displays are probably not imminent.
Almost twice as many pixels require almost twice the bandwidth to drive over a cable. Thunderbolt at 10 Gbit/s wasn’t fast enough to drive 4K, which needs about 16 Gbit/s. Thunderbolt 2 at 20 Gbit/s can drive 4K, but not 5120×2880, which needs 28 Gbit/s.1 The only promising standard on the horizon is DisplayPort 1.3 at 32 Gbit/s, but that spec is being finalized later in 2014, which means we’re probably still years away from anything supporting it.2
Many GPUs haven’t been powerful enough to drive much at 4K resolution even if they could output it somehow, so 5120×2880 would be out of the question.
Fortunately, that last one is no longer true at the high end. It’s just the first two holding us back now, but they’re also the slowest to change.
I suspect that 5120×2880 on the desktop is still 2–3 years away.
But I think Apple has already shown us how they’re going to do 27″ Retina. Apple’s not a difficult company to predict if you pay attention. My hopes for a 5120×2880 display for the new Mac Pro were blinding me to the obvious clues to what will very likely happen instead.
Before the 15″ Retina MacBook Pro (the first Retina Mac), power users buying the 15″ usually opted for the “high-resolution” option at 1680×1050 instead of the lower default of 1440×900. But when the 15″ Retina MacBook Pro was released, its panel was a “2×” version of 1440×900 — a step down in logical resolution for power users. To make up for the loss, Apple introduced software scaling modes that simulated 1680×1050 and 1920×1200 by rendering them at double-size and then scaling the image down to the physical 2880×1800 pixels. GPU performance is reduced slightly, but otherwise, these higher-resolution scaling modes are effectively “free” — the pixels are so small that the reduced image quality from downsampling is barely noticeable.
A few months later, the 13″ Retina MacBook Pro was released with the same trick: a relatively low native resolution of 1280×800 logical pixels (2560×1600 physical pixels), but with simulated higher resolutions.
To bring Retina to the 27″ iMac and 27″ Thunderbolt Display, Apple doesn’t need to wait until 5120×2880 panels are available. They can launch them at the next-lowest common resolution and use software scaling to let people simulate it if they want, or display things slightly larger at perfect native resolution.
That next resolution down, of course, is 4K.
The hardware and software to support 4K is already available. Thunderbolt 2 drives it well. Only very recent GPUs can drive it, but only very recent Macs with decent-to-powerful GPUs have Thunderbolt 2.3
All Apple needs to do to deliver desktop Retina is ship a 27″ 4K Thunderbolt 2 monitor and enable the software scaling modes for it in an OS X update.
We just learned that it’s possible to sell a 28″ 4K display that’s at least halfway decent for only $700 and a 24″ for $1300. With Apple’s supply chain, they could almost certainly sell a 27″ 4K Thunderbolt 2 display for $999–$1299 now and a 27″ Retina iMac later this year at pricing similar to today’s 27″ iMac.
I’ve gone back and forth on this, but I think both a Retina iMac and a Retina Thunderbolt 2 Display will be released in 2014.
At 60 Hz, the minimum needed for comfortable general use, and 32 bits per pixel. You might argue that only 24 bits are necessary, but 5120×2880 at 60 Hz and 24-bit still needs 21.2 Gbit/s — more than Thunderbolt 2.
Another option would be to make a 5120×2880 display that requires two cables, but they’d need to be plugged into two different Thunderbolt 2 buses. This would effectively monopolize 4 of the 6 Thunderbolt ports on the new Mac Pro and wouldn’t be compatible with the recent Thunderbolt 2-equipped Retina MacBook Pros at all. I don’t see Apple doing this. ↩︎
Note from that Wikipedia page that DisplayPort 1.2, the standard that became fast enough to support 4K and has only recently become widespread, was finalized in 2009. ↩︎
Only the new Mac Pro and the late-2013 13″ and 15″ Retina MacBook Pros have Thunderbolt 2. The MacBook Air, iMac, Mac Mini, and non-Retina MacBook Pro still only have first-generation Thunderbolt.
The Verge, which still uses target="_blank" on inline links in 2014 (don’t worry, I removed it for you):
A new Gmail “feature” will let you simply type in anyone’s name into Gmail’s “to” field and send them an email. Google announced the new Google+ integration on its Gmail blog today, but company representatives have clarified to The Verge that — by default — anyone on its social network will be able to send messages to your Gmail inbox.
This has to be a mistake. Surely Google will change this from opt-out to opt-in.
They probably will, but only because of this negative press. They were almost certainly going to launch it as opt-out, hoping most people wouldn’t notice. Or — giving them the benefit of the doubt, which probably isn’t warranted — the responsible people at Google might actually think they’re being helpful, assuming that all Gmail users are also Google+ users (they’re often counted that way…) and that this would be a helpful feature.
I don’t know why anyone’s surprised. To be clear, for anyone who thinks Google is some benevolent, selfless entity handing out free services to everyone out of the goodness of its heart:
Google’s leadership, threatened by the attention and advertising relevance of Facebook, is betting the company on Google+ at all costs.
Google+ adoption and usage is not meeting their expectations. Facebook continues to dominate. It’s not working. They’re desperate.
Google will continue to sell out and potentially ruin its other properties to juice Google+ usage. These efforts haven’t worked very well: they juice the numbers just enough that Google will keep doing this, yet will keep needing to do more.
Making Google+ succeed at all costs means exactly that. All previous rules are out the window. Google will eventually violate every formerly held principle if it might help Google+.
You, the users, are just along for the ride. You’re just eyeballs. Body parts and ad-targeting data. Google doesn’t care about you at all. You’ve tolerated enough already that it’s pretty clear you’re not really going anywhere.
I stabbed The Verge briefly in yesterday’s post for using target="_blank" in their link markup, which tells browsers to always open the target in a new window. (Modern browsers usually have options or extensions to put them into new tabs instead.)
A lot of people have asked me to clarify whether forcing links to open new windows or tabs is actually bad behavior (and why), or just outdated markup that could be replaced with a new HTML5 way to do the same thing. I meant the former. People have been arguing about this for over a decade, so I’ll keep my position brief.
Forcing links to open in new windows has two main purposes:
To avoid disturbing an important session in progress for a temporary digression, such as FAQ/documentation links in the sidebar when you’re doing online banking.
To “keep people on your site”, ensuring that even when visitors navigate away, your tab is never closed and the user is forced to interact with it again later. Maybe they’ll let the ads refresh a few more times or click another story!
I believe the former is justifiable, the latter isn’t, and reading a news or blog article does not qualify as an undisturbable session for most people. And I think over a decade of user confusion and frustration resulting from target="_blank" backs that up.
Most people know how to open your article’s outbound links in new tabs or windows, especially readers of a tech site. Modern browsers make multiple-tab/window management very easy for almost everyone who wants them, and the people who don’t know how to manage them usually don’t want them.
The best practice for the modern web is to let people manage their own windows and tabs.
Good read. He makes a strong case for trying 175°F brewing:
There are people who buy AeroPresses who use it differently, and the first way they use it differently is they don’t use 175 degree water. They say, oh you can’t possibly brew coffee at 175 degrees. My answer always is, well, you can use any temperature your heart desires, but you owe it to yourself to try 175, because whenever we do blind tasting, whether it be for just average people or professional coffee tasters, they invariably choose 175. I would say that the average person who had an AeroPress has never tried 175, even once.
He’s right for me — I hadn’t tried it. So today, I brewed both of my cups at 175°F: the first using the original instructions to the letter (including dilution), and the second using my usual method of inversion, filling it most of the way up, and not diluting. Both tasted too sweet and weak to me, with my method being slightly less weak. Not my style. I’m going back to boiling the water for now, but I’m glad I tried it.
(For whatever it’s worth: the SCAA cupping standard for brewing temperature is 200°F.)
My kitchen is lit by 14 little recessed halogen PAR20 bulbs. They use 50 watts each, so it takes a whopping 700 watts to fully light one of the most commonly used rooms in the house. (I gather that when the previous owners remodeled it in 2005, the use of tons of tiny recessed lights was in style — electricity usage be damned.) And with this many of them, it seems like they’re constantly burning out, losing a $10 bulb every month or two. It’s wasteful and annoying.
I’ve been eyeing LED replacements for a while, but they all looked too primitive until recently: they had giant ugly metal fins, they looked harsh because they lacked good diffusers, and they cast a narrower light beam than the normal halogens.
But LEDs are advancing so quickly that I decided to try two current models that were well-reviewed and install one each, side-by-side with the halogens, for comparison:
Both LED bulbs are about the same size and weight as halogen PAR20s, and both are reasonable-looking.
Both LEDs have a brief but noticeable startup delay of less than a second, like most Philips LED bulbs. I usually find startup delays fatally annoying, but I’ll tolerate it for these since good PAR20 options are limited.
The three bulbs’ advertised color temperatures seem accurate. The Feit is slightly cooler than the halogens, while the Philips is slightly warmer. (It’s a little hard to gauge the colors accurately from the photo since the cabinets are a cream color, warmer than neutral white.)
The Feit is slightly brighter than the halogens. (There’s no way those halogens are putting out their advertised 570 lumens.)
As you can see, the Feit is creating a similarly wide, diffuse beam as the halogens — in fact, it’s doing an even better job of it. The Philips is a bit too narrow on the cabinet doors, although it’s less noticeable at counter level. But you can see that the Philips isn’t very diffuse — look at the difference in the two shadow directions on the cabinet-door handles. Shadows cast by the Feit approximately match the halogen’s shadows, while the Philips shadows are much darker and sharper.
The Philips also has the same odd orange-pink tint as every Philips LED bulb I’ve owned. Some people don’t mind it, but I really don’t like it.
I prefer the Feit overall, and I’m pleasantly surprised that there doesn’t seem to be much of a downside compared to halogens except the slightly cooler color temperature. Finally, PAR20 LEDs are good.
So good that I ordered 13 more, which will pay for themselves in only a year.
It’s not yet clear exactly how Google plans to use Nest, but the company obviously sees it as an important part of its future. A combination of Nest’s home solutions coupled with Google’s language recognition could give Google its strongest path yet into your home.
YuktiPro iDo positively focuses individuals and teams on their goals. Designed using neuroscience research, iDo helps you or your team stay focused, track progress, share results, and maximize engagement in the most natural way.
iDo creates an informal yet structured daily discussion to track progress on large tasks. Team leaders can instantly see the big picture, foster awareness and recognition, and raise positivity, engagement, and happiness in their teams while reducing needless meetings and procedures.
iDo gently prompts you to reflect on your day in the evening and maintain a goal-centered diary of completed tasks. The next day, iDo jump-starts your morning by connecting you with your progress and goals. You’ll start to see which goals naturally attract more attention and passion, and what really drives your productivity.
The defensive FAQ by Nest to alleviate widespread fears about the Google acquisition has been quoted extensively. The whole thing (it’s short) is worth examining critically.
Before we dig in, I want to acknowledge what I consider the first great Nest partnership. I’m not talking about Google. I’m talking about the one between you and the team here at Nest.
How patronizing.
Let’s all give each other a big hug! We’re just a $3 billion company that just got acquired by a massive advertising conglomerate that controls, tracks, and records an ever-expanding amount of everything that people do with all modern technology. We’re all friends and everything’s great. Give yourselves a big round of applause for being such great customers!
Keep this next part in mind:
Will Nest and Google products work with each other?
Nest’s product line obviously caught the attention of Google and I’m betting that there’s a lot of cool stuff we could do together, but nothing to share today.
This is fairly straightforward and obvious: the division between Nest and Google products and services will blur, leading to merged products in the future. Of course. Why would Google buy them if they didn’t have something like that in mind?
The definitions of “products” and “services” can be broad. Maybe the thermostat is still a Nest-branded product, but the weather service it connects to is a Google service. Habit analysis and prediction could also be a Google service. (It already is.) Obviously, Google and Nest should be considered one entity with one product line and shared services in the future, regardless of whose name is painted on the front of the thermostat.
So when I see so many people only quoting this part and thinking it changes anything, it’s pretty easy to have a more cynical (and realistic) interpretation:
Will Nest customer data be shared with Google?
Our privacy policy clearly limits the use of customer information to providing and improving Nest’s products and services. We’ve always taken privacy seriously and this will not change.
Statements like this should be interpreted as if you’re a lawyer trying to find a loophole. (Because theirs will.)
“This will not change” only refers to “We’ve always taken privacy seriously”. In other words, the sentence only says “We will always take privacy seriously”, which doesn’t mean anything and should be disregarded. So we’re down to this:
Will Nest customer data be shared with Google?
Our privacy policy clearly limits the use of customer information to providing and improving Nest’s products and services.
The question in bold is not answered by the following sentence, or anywhere else. Asking a question without answering it is a diversion, containing no information, so it can also be removed. We’re left with only one sentence that actually says something:
Our privacy policy clearly limits the use of customer information to providing and improving Nest’s products and services.
It’s meant to sound reassuring, but their privacy policy can change whenever they feel like it. And remember, the definition of “providing and improving Nest’s products and services” can be very broad.
Think of how much more accurate your Nest thermostat’s predictions could be if it integrated with a few Google services.
If you’re using Google’s services enough to give them a pretty good idea of where you are and what you’re doing,1 Nest could automatically turn your heat on so it reaches the ideal temperature at exactly the time you’re most likely to arrive home based on your location, travel speed, the route you usually take, and current traffic conditions. How clever and impressive! It’s even environmentally friendly!
Google won’t break into your home. You’ll invite them in.
An interaction could be something implicit and obvious, like using Google search or Maps to navigate or find something. Or it could be something you don’t expect to give Google any tracking information, like viewing a web page with an AdSense or +1 embed, but that’s probably enough.
They have so much data about you, your browser, your phone, your computer, and your current IP address that it doesn’t take much for them to make a pretty good guess at who you are, where you are, and what you’re doing most of the time. ↩︎
Brett Terpstra invited me to be on his podcast to talk about the realities of indie life, time management, job security and diversity, employing people, your audience’s expectations, the crowded App Store, the future of App Store reviews, podcast and radio ad effectiveness and sales tracking, customer trust in the Mac App Store, dog sizes, stouts, LED light bulbs, bluegrass, and more.
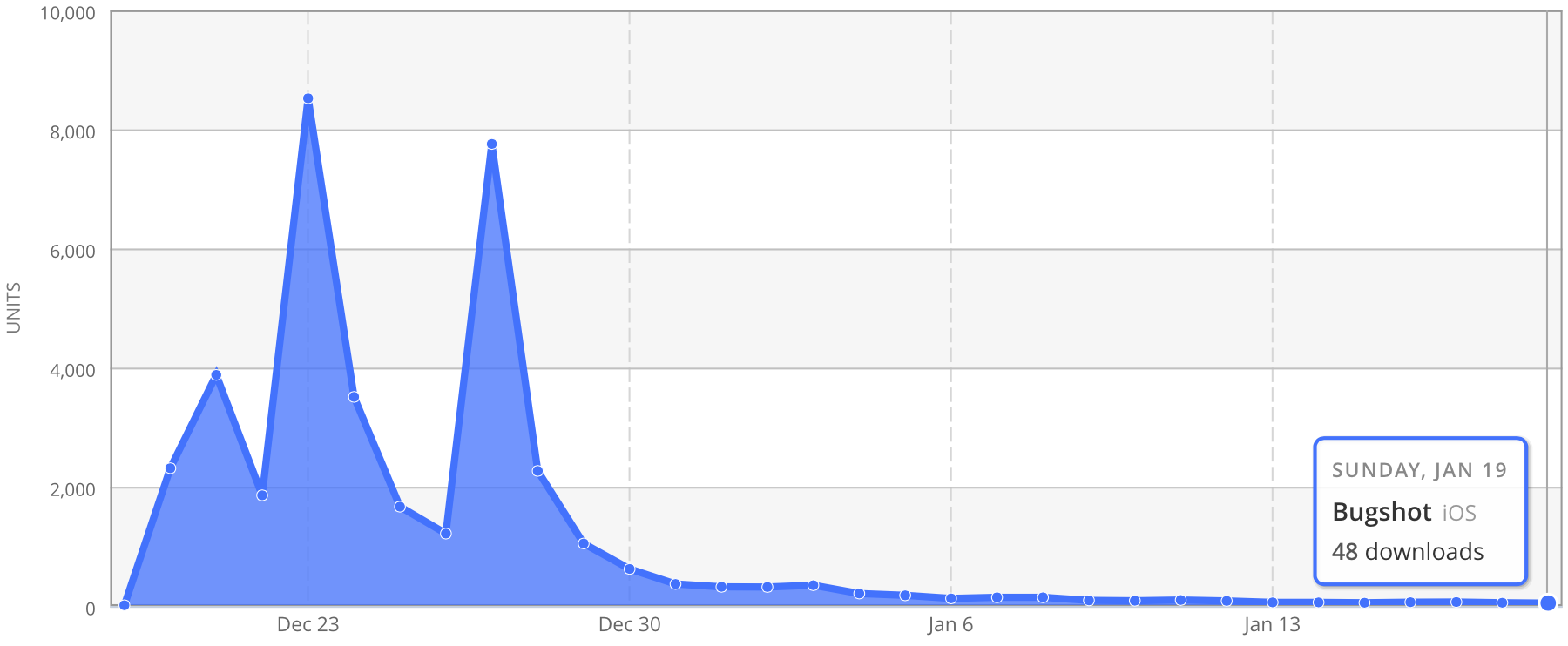
Last summer, I spent about two weeks writing a little app called Bugshot to help me report and track app rendering bugs during the iOS 7 transition, learn the iOS 7 style a bit myself, and jump-start my iOS development motivation again after losing my soul to paperwork all spring. It succeeded at all of those.
It was also an experiment in pricing: I launched it at $0.99 — my first app ever at that price — to see how it would sell once the launch buzz died down. It was abysmal. Average daily revenue in November was $4.18, and in the first half of December, it had fallen to just $3.28.1
As a money-maker, it was a failure, but it was very educational. I decided to learn one more lesson from it: a month ago, right before the iTunes Connect holiday shutdown, I quietly made it free and didn’t tell anyone. Some of the app-tracker sites picked it up, which caused a huge spike in downloads:
But like all App Store trend lines, it quickly went down, settling at around 50 downloads per day recently, and I bet it will continue to fall.
Now I’m taking the Bugshot experiment in a different direction: open source.
I didn’t want to just open-source the entire app. That may be slightly educational to some, but it wouldn’t be very useful.
Instead, I’ve taken the last few days to build BugshotKit.
I’m starting the Overcast beta soon,2 and I wanted an easy way for my testers to report (non-crash) bugs and provide UI feedback. I also wanted a way to remind myself of UI or feature ideas easily, and I’ve occasionally needed to view the error console on the device when tracking down difficult bugs.
BugshotKit addresses all of these: it’s an embeddable Bugshot annotation interface and console logger, invoked anywhere in your app by an otherwise unused gesture (e.g. a two-finger swipe up, a three-finger double-tap, pulling out from the right screen edge, etc.), that lets you or your testers quickly email you with helpful details, screenshots, and diagnostic information.
It contains most of the interesting Bugshot code,3 some interesting console stuff, and some useful functionality to developers.
I’ve learned a lot from Bugshot, and I’m still learning from it. Now, I hope I can share some of the benefits with other developers.
From its launch in July until I made it free in December, Bugshot made a total of $4,724.67. This was heavily front-loaded, making $4,088.11 in July and August alone. ↩︎
I’ve never had so many requests to be on a beta before. I appreciate the interest, but I’ve gotten far more requests than the 100-device limit. ↩︎
I’ve changed the blur tool from a “pixelate” style to a real blur because the pixelate filter used GPUImage, which, despite being awesome, is a massive dependency. I didn’t want BugshotKit to have any dependencies. ↩︎
You’ve heard about Igloo before: we’re an easy-to-use, cloud-based
intranet platform. We say you’ll like it, but you don’t have to believe
us: we’ve made some case studies so you can hear it right from our customers:
The analysts agree, too: Igloo just won the the Global Enterprise Social
Networking Product Leadership Award, beating out Microsoft SharePoint,
IBM, and Jive. Read the full report.
And if you can’t convince the powers-that-be to try Igloo (even though
it’s free to use with up to ten people), Igloo’s Social Intranet Tour is
coming to a city near you.
Send your people our way. We’re here to help.
Thanks to Igloo for sponsoring Marco.org this week.
I’d been waiting for a detailed review of this coffee maker, and apparently I missed this one back in October. (Via Conrad Stoll.)
To serve my wife and me, I fire 2–4 AeroPress cups per day. The Bunn Trifecta looked like it was close to an automated AeroPress, and I was curious if it could save me any significant time while still producing AeroPress-quality coffee.
After reading this review, I don’t think I’m interested anymore. It sounds like it’s the same or worse than the AeroPress in almost every way — less control, can’t use a fine grind, some French Press-like sediment in the cup, the same amount of prep, almost the same amount of work, a similar amount of cleanup, and about the same max capacity per brew. And you could buy about 22 AeroPresses for the cost of the Trifecta MB.
At 39 minutes, Myke asked how music promotion works today. I’ve quoted part of John’s response, with some slight editing and paraphrasing to read more easily:
[40:30]
[Ten years ago,] you were dependent on this whole cultural architecture of magazine writers, newspaper writers, college radio, commercial radio, public radio… and if your record got into the stream, and the right person liked it and talked about it, then pretty soon you’ve created a storm of interest that started with one or two people who decided that this record was something that really mattered.
If you couldn’t get those people to take an interest in your record — because of course everybody in the world knows who those few people are, and they’re inundating them with albums — if you couldn’t get that person to take the time, or if they just didn’t like it, then you’d be struggling, grasping at every opportunity to get someone further down the food chain to take an interest in this album. …
[43:07]
Well, five years ago, all of a sudden the conventional wisdom started to change. “Oh, no, we don’t have to do any of that anymore! You just put it on the internet, everybody listens to it, and ‘the crowd’ decides! And you don’t have to do any of that bullshit anymore. You can just tweet about your record, and everybody’s going to listen to it and love it!”
And for a brief moment, when the internet was still comprised mostly of all the right people, it was just the cool kids that were on there. Clap Your Hands Say Yeah could put out a record on Myspace, and the cool kids would all get it.
But, of course, that window was short-lived. Now, we’re back to a world where everybody’s on the internet, and nobody cares. Nobody’s following your tweet link to your record anymore! Except your fans, people who already like you.
My Twitter feed is now 85% links to people’s Kickstarters and YouTube videos. And I only follow people I know! Imagine following your favorite bands — it would be never-ending. Everybody’s trying to promote themselves the same way.
The problem is now, if you hire a publicist, what are they doing? They’re just tweeting about it, too, because the magazines are gone, the record stores are gone… it’s anybody’s guess how to promote a record now. …
[45:28] I hate to sound curmudgenly, but … what is inevitable is that the mean quality of everything is declining. In the early ’70s, it was very expensive to make a record, and you had to be really good at it to even get into the studio to give it a shot. The record companies were very selective, and the music that made it all the way out to the marketplace was astonishingly good. Think about the music that came out between 1962 and 1972: what an astonishing quality of music, in every genre. Ten different genres of music were invented and perfected.
Now, we live in a world where there are probably more records coming out this week than what came out in all of 1967. All of that quantity probably hasn’t produced a single record that was as good as the worst record from 1967. Everything is easier to make, so more people are making it, the standard is so much lower for what you need, and it’s a confusing din.
As a culture, we are satisfied with worse, because there’s so much more of everything.
When a Marvin Gaye record came out 40 years ago, presumably, you went and spent your record-buying allowance on it, and you brought it home and listened to it exclusively for 2 weeks. It was an investment. This was it! You’re going to listen to this, or you’ve got an AM radio and a newspaper.
Now, we’re just clicking through songs. “How does this one sound? Oh, that’s good. How does this one sound? Pretty good. This one’s good.”
We’re just flipping through index cards.
This is equally true in all media today, including software.
This is why a hundred other sites are trying to be Daring Fireball, why everybody’s starting a podcast, and why nobody’s buying your app in the App Store.
The democratization of media production and distribution over the last few decades has worked incredibly well. Overall, it’s a net win for society. But the downside is that everything’s now extremely crowded.
There’s a lot of money and attention out there to go around, but there’s also a lot more competition for everything.
I had a good time joining Dave and Jaimee to talk about Arrested Development S4, the Star Wars prequels, internet comments, podcasting, and other topics that are completely fresh and new to the internet.
I couldn’t believe that I’d been opted-in, without my permission, to any new product — and I was stunned when I saw how much it cost. And further surprised when I saw that I would have to make a phone call to deal with all this.
I waited to link to this at first, because surely, I thought, this has to be a misunderstanding, a phishing scam not actually from Network Solutions, or some other reasonable alternative explanation.
“WebLock is intended for the top 1 percent of Web.com’s customers who own some of the world’s most highly-visible and valuable web properties.”
I bet the real reason they’re auto-enrolling this helpful “service” for the top 1% of customers is because the top 1% contains many huge companies and bulk registrants that are less likely to notice this extra fee.
Apple’s currently featuring the Sunrise app in the App Store.
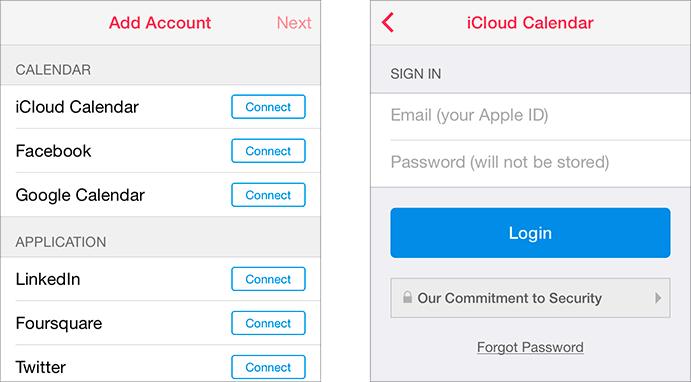
Upon first launch, Sunrise invites you to create an account, then asks you to add a calendar. The first option, “iCloud Calendar”, brings you to a screen where the Sunrise app itself, in its native interface and code, solicits your Apple ID (iCloud) email address and password.
This is apparently OK.
I first saw Neven Mrgan point this out (good replies there), with some additional commentary from Michael Tsai. I couldn’t believe it, so I downloaded the app myself and took these screenshots.
Sunrise claims that they’re not storing the credentials and are instead just getting a login token of some sort from iCloud. (It’s unclear whether they’re transmitting your email and password to their servers and getting the login token from there, or doing the exchange from the device.) But that doesn’t matter at all.
No app or website should ever be asking for a high-security username and password directly, especially given how much is tied to your Apple ID. What year is this?
It’s downright dangerous that Apple not only let this through app review, but is promoting it.
I don’t think that’s a valid justification for a young company that has already had a security scare to ask for a high-security username and password that many people tie to their entire online lives and the security of all of the files on their computers.
Oh, and they do transmit them to the server, rather than getting an authentication token on-device:
When you type in your iCloud credentials, they are sent to our server only once in a secured way over SSL. We use them to generate a secure token from Apple. This secure token is the only thing we store on our servers, we never store your actual iCloud credentials.
This is better than storing your password in their database, but it’s still not very secure by modern standards: they’re still taking on the responsibility of transmitting it securely from the app, receiving it securely on the servers, sending it back to Apple securely to get a token, ensuring no tools, proxies, or analytics are caching or logging it along the way, and ensuring that their servers aren’t quietly hacked and nobody’s monitoring the application to capture the credentials in flight.
Many readers have blamed Apple for this, mostly because the lack of official iCloud APIs and support for OAuth (or a similar scheme). I agree. But the ideal “Apple way” isn’t to do something really horribly until they have time and motivation to “do it right” — it’s not to do it at all.
It’s better not to permit apps to access customers’ iCloud account at all (beyond the official, secure APIs) than to allow any app to collect them insecurely and do whatever they want with them.
Regardless of whether you agree that this is Apple’s fault, it will definitely be Apple’s problem when an app like this has a security breach that compromises hundreds of thousands — maybe millions — of Apple IDs.
Brent Simmons got some great advice out of Lex Friedman about how to run a small podcast-ad network that needs to exist, and previously did, but currently doesn’t. They’re both calling for someone to make a network like that again.
Podcast geeks jumping into ad sales is a recent phenomenon, mostly out of necessity because there’s no AdSense for podcasts. And trust me, the world is better off without that.
AdSense (and later, better web ad networks like The Deck) removed much of the reason for most independent bloggers to join blog networks. The lack of accessible ad networks in podcasts, and the sheer amount of work it takes to sell directly, is a huge reason why podcast networks are relevant and common. If you could easily outsource just the ad-sales part separately, and change it at will if things don’t work out with someone, there’s much less reason to join a podcast network. You could host your files on SoundCloud or Libsyn, put the show on Squarespace,1 use your own domain name, teach yourself basic editing in GarageBand (it’s easy), and be completely independent.
I tried selling the sponsorships myself in the early days of ATP, but was quickly demoralized and jaded by the reality of that job. It takes a lot of email, some long phone calls, a lot of paperwork, and a lot of nagging to get past-due invoices paid. It’s common for sponsors to ignore your payment-due dates and pay months after you actually do the sponsorships. Most big sponsors have their own way they “need” to work, blaming “the accounting department” or “policy”, and these arbitrary accounting rules and policies often mean that your ad salesperson has a lot of work to do and you’re not getting paid for a long time. (This dance isn’t new to most contractors.)
Even in the best cases, working with the easiest sponsors, you still need to schedule each sponsorship, bill for each sponsorship, get a script or bullet points (which sometimes needs a phone call), prepare those materials while recording each show, read them during the show, link to them on the website, and follow up with them afterward if necessary. It’s a lot of work.
I say all of this not because I dislike sponsors — they pay far more than we’d be likely to get from direct listener donations, and if we forced a paywall, nobody would listen and our show would be irrelevant. If we didn’t have sponsors, we wouldn’t make enough to be worth the substantial time it takes to produce the show. Sponsorships enable podcasting as we know it today. There are some exceptions, but not many that anyone has heard of.
But the job of a podcast-ad salesperson isn’t trivial. That’s why we outsourced it, and why it’s worth losing a significant percentage of our income to commissions to do so. I wouldn’t recommend getting into this business unless you’re prepared to deal with, and would enjoy, the day-to-day reality and tedium of it.
And if you can handle people like me bugging you every week to get our invoices paid.2
If you don’t care about download stats, you can even host the files on Squarespace. But if you’re selling ads, you’ll need download stats.
Squarespace could take a lot of Libsyn’s customers if they offered podcast download stats, but it doesn’t look like they want to be in that business at a bigger scale than what they’re offering now. ↩︎
It’s sad that this has come to an issue of courts and regulatory bodies. The real problem is that there’s nowhere else to turn. There is no tangible consumer choice.
Chilling.
I expect zero help from the U.S. government on this. They’ve repeatedly shown over the last 20 years, regardless of which political party is in power, that they’re incapable of and unwilling to regulate broadband in a way that helps consumers or technological progress at all.
We’re going to have to work around them. But I don’t see an effective, sustainable way to do that yet. There may not be one.
Keynote’s presenter-display defaults were always designed for the average case: someone who crams a lot of text into their slides and doesn’t use presenter notes at all.1
Of course, that’s likely to be a terrible presentation in which everyone in the room, including the presenter, is just clumsily reading off the slides constantly. But that’s how most people use Keynote and PowerPoint.
Now they’re making it harder to do it any other way.
I continue to wonder what, exactly, is better about the new iWork apps in practice. I haven’t found a compelling change yet.
Anyone at Apple who considered presenter-note usage would never have picked those font settings, and probably would have made it possible to change the note formatting for all slides at once. ↩︎
Jonathan Mahler’s When “Long-Form” Is Bad Form in The New York Times this weekend has generated a lot of discussion. I saw it as a sloppy collection of disparate rants with mixed validity, but one resonates:
The problem is that long-form stories are too often celebrated simply because they exist. And are long. …
When you fetishize — as opposed to value — something, you wind up celebrating the idea of the thing rather than the thing itself.
Mahler quotes from (but doesn’t link to, for no good reason) last month’s Against “Long-Form Journalism” by James Bennet, editor of The Atlantic. It’s much better-written and goes deeper into the “long-form” issue:
In the digital age, making a virtue of mere length sends the wrong message to writers as well as readers. …
As a writer, I used to complain that my editors would cut out all my great color, just to make the story fit; as an editor, I now realize that, yes, they had to make my stories fit, and, no, that color wasn’t so great. The editors were working to preserve the stuff that would make the story go, to make sure the story earned every incremental word, in service to the reader. Long-form, on the Web, is in danger of meaning “a lot of words.”
I faced a lot of pressure when running Instapaper to embrace the “long-form” fetish, which I resisted as much as possible. With whatever influence I had by starting the read-later-app genre, I tried to take the focus away from length and more toward context switching.
Read-later apps let you separate reading from finding, since they ideally happen with different mindsets and environments. This is necessary not because browsing aggregators, timelines, and feed readers is given too little time — people happily devote hours to it — but because the goal is to “get through” them and keep checking for new items, keeping readers in a skimming, active, dismissive mindset that’s hostile to attentive reading.
Instapaper’s usage data backed this up: there was almost no correlation between article length and number of saves on Instapaper. People routinely saved everything from three-paragraph Lifehacker posts to 10,000-word feature articles. The most-saved sites were usually just the most popular sites read by the kind of people who knew about Instapaper, not just the longest articles they found.
Nobody was saving Lifehacker posts because they couldn’t read three paragraphs right then: they saved them because they wanted to attentively read them, which wasn’t going to happen in their current context.
But the “long-form” fetishization exploded around me, despite my efforts to separate read-later apps from that term.
Skimming fluffy articles and social timelines all day is like eating junk food all day. Eventually, you feel horrible, burn out, and just want something real. After decades of evolution, experimentation, and testing, web producers have honed the formula for addictive junk content to perfection. We have infinite junk available to us on demand, on any subject, from small rectangles available in our pockets, all day, every day. It’s no surprise that a growing number of people have begun fetishizing salads.
The problem is that long doesn’t mean good — it just doesn’t look like most of the junk. Too many people now ask for (and produce) “long-form” when they really want substantial. It’s entirely possible to be substantial without being long, and good editors have helped writers strike that balance for centuries. Emphasizing and rewarding length over quality results in worse writing and more reader abandonment.
Smart writers, editors, and publishers will recognize the difference and give people what they really want, rather than what they’re asking for.
I’ve been beta-testing this for a while and it’s awesome. It’s also very generous of them to make this a free update. (I advised against that, given the modern App Store economy and the massive scale of this update, but they’re too nice.)
Before, Dark Sky was a great secondary weather app, performing a role that the others didn’t (very accurate short-term precipitation predictions) but without the basics like temperature and forecast data.
Now, with those basics added, plus major upgrades to the short-term precipitation features, the new Dark Sky can be your only weather app. (If you live in the United States.)
Comparisons to recent indie favorites Weather Line and Check the Weather, both full-featured weather apps that integrate Dark Sky’s short-term precipitation API, will naturally arise. Weather Line and Check the Weather are both primarily about general weather info with some Dark Sky features added, while the Dark Sky app is still focused mostly on short-term forecasting with some general weather info added.
You can buy all of them for just $8 and see for yourself which one works best. For my usage, caring mostly about short-term forecasts and a bit about the rest of the week, the new Dark Sky is my favorite.
The mobile web and mobile apps have never played nicely together. Want to send a web visitor to a specific spot inside your app? You could use deep links for that, but if the visitor doesn’t already have your app installed, you’re SOL.
Not anymore. Tapstream’s Deferred Deep Links pass parameters to your app before it’s installed, right through the great App Store firewall.
Let that sink in.
It means that for the first time, you can navigate new users to a specific spot inside the app. This is great for building automatic viral loops (if a user installs the app by following an invite from a friend, then automatically follow the friend once the app is installed), or for creating more compelling user acquisition campaigns (“Unlock extra levels if you tap this ad”).
These magical Deferred Deep Links work thanks to Tapstream’s massive attribution back-end (see the technical behind-the-scenes), and what they can do for you is practically unlimited. And they’re completely free to use.
Stories like this are why I’m so hard on apps that ask for your email credentials. If someone has access to your email account, they can get access to everything else you do online pretty quickly by password resets. (In related news, I’ve enabled two-factor authentication on a lot of accounts recently, and I suggest you do the same.)
The problem, as always, is people. These hacking stories increasingly include fake calls to big web services’ support lines, begging the human agents for password resets. It doesn’t matter how many non-repeated letters, non-consecutive numbers, and unique symbols are in a password that’s new every 6 months and not similar to the previous 10 passwords if attackers have no need to crack it.
Services have always needed to allow such requests because people really are legitimately that forgetful, and their online lives really are that turbulent. People forget their website passwords and lose access to their email accounts all the time.1
Smart services are closing these doors, but it’s not easy. If there’s any way for a human to override the security mechanisms if someone on the phone is crying and sounds legitimate, attackers can get in. And if there’s not, you’re going to have a lot of legitimate customers locked out and crying.
It’s not a safe assumption that people will always have access to the email account they signed up with. Often, people use school or workplace accounts that get deleted or redirected out of their control when they graduate, leave, or get fired.
And this is assuming that they typed their own email address correctly into your registration form in the first place. ↩︎
He disagrees with most of Jared Sinclair’s criticism, and I agree with Dr. Drang on almost everything. There are some flaws, including the swipe-gesture conflicts on the week pane, but I think they’re minor, and most of the app is designed well.
Most of Sinclair’s criticism reads more like an argument against current design trends and fashion. “Trendy” isn’t always a bad word — trends have always been used (and created) when applying design to real-world problems. A designer’s job is to balance function with fashion.
How badly would an app be received today, and how boring and dated would it look, if it did everything Sinclair suggested?
In 2011, when Windows 8’s “Metro” was in beta and everyone had high hopes for it, I wrote:
The question isn’t whether Metro will be good: it probably will be. … But how will their customers react?
Will Metro be meaningfully adopted by PC users? Or will it be a layer that most users disable immediately or use briefly and then forget about, like Mac OS X’s Dashboard, in which case they’ll deride the Metro-only tablets as “useless” and keep using Windows like they always have?
Microsoft’s customers don’t like change. They’re accustomed to getting everything they want, exactly as they want it, with no surprises. They won’t tolerate anything else.
If Microsoft releases anything too different, enterprise customers will simply refuse to buy it, demanding that Microsoft keep selling the old version indefinitely. And every time, Microsoft caves, because what else are they going to do? They’re desperate for upgrade revenue from business customers who see diminishing returns and increasing transition costs with each new version of Windows and Office.
While the software giant originally released Windows 8.1 last year with an option to bypass the “Metro” interface at boot, sources familiar with Microsoft’s plans have revealed to The Verge that the upcoming update for Windows 8.1 will enable this by default. Like many other changes in Update 1, we’re told the reason for the reversal is to improve the OS for keyboard and mouse users.
Bye, Metro.
It’s not that Microsoft is incapable of making radical changes. Not only was Windows 8 the most bold move they’ve made since Windows 95, but it wasn’t even bad. It wasn’t great, but it wasn’t bad. Microsoft truly innovated with the UI to a greater extent than we’ve ever seen from them.
Their customers, as usual, smacked them back into line.
Adoption has been abysmal, PC manufacturers are advertising Windows 7 downgrades as features (much like they did from Vista to XP), and the Surface tablets have sold very poorly. Windows 8 has been one of the biggest disasters in Microsoft’s history.
They did everything that the press, analysts, and prevailing wisdom at the time were telling them to do. Everyone was pressuring them to be more like Apple, so they tried.
The problem isn’t that they botched it (although they did, in some ways). The problem is that Microsoft isn’t Apple, and Microsoft’s customers aren’t Apple’s customers. They tried selling a more Apple-like attitude to their customers, most of whom don’t want and won’t tolerate an Apple-like attitude. That’s why they’re not Apple customers.
Microsoft’s customers have always demanded, and will always get, exactly what they ask for. That’s the reality of serving the low- to midrange-PC business, and it’s sure as hell the reality of the enterprise business.
Microsoft’s biggest strategic mistake over the last five years has been forgetting who their customers really are.
I don’t know how any good people make money in the game business anymore. Seems like the only way to have a decent chance of making a living is to be as sleazy as possible.