I use a Fujitsu ScanSnap S510M (which has since been replaced in their lineup) and love it. I’ve scanned, shredded, and recycled more than 4,200 pages so far that could have been taking up space in my house, but now aren’t.
As part of my workflow, which isn’t very interesting, I’d like OCR software to recognize the text in scanned documents and embed it under the page images in their PDF files. With the text embedded, I can search the documents with Spotlight and attempt to organize them more easily.
The ScanSnap came with ABBYY FineReader, which does an acceptable job, but degrades the image quality noticeably when it saves the text-embedded PDF copy. It’s enough of a problem that I’m not comfortable deleting the original, and I’d rather not keep two copies of every file around, so I tried to find an alternative that could output better-quality PDFs with text.
NOTE: I know there are more OCR apps than this. I probably forgot yours. There’s only so much time in the day, so I picked the ones that people recommended most and that seemed like good fits for what I want.
To test these apps, I made them all process a scan of a common document: a New York driver’s license eye-test form. (It was the last thing I scanned. I’m still 20/20, but probably not for much longer.)
ABBYY FineReader
Bundled with many ScanSnaps, based on ABBYY’s own OCR engine.
$59, based on Nuance’s commercial OmniPage engine. This app does a lot; OCR is just one feature.
Perfect image quality.
Very few OCR errors.
Can be automated with AppleScript, although the windows still get shoved in your face while it’s working.
Acrobat
It also came with the ScanSnap, but testing it would require me to… install Acrobat. On my Mac. Where things work.
No.
I hate having to write “conclusion” headers
Only PDF OCR X and PDFpen preserved perfect image quality, so they’re the only options for which I’d feel comfortable deleting the original PDFs and keeping only the embedded-text copies.
PDF OCR X looks… like someone wrapped a bare-bones interface around an open-source OCR library.
PDFpen is nicely designed and built by an extremely well-respected, well-established Mac developer, and it’s available in the App Store. This means that it’s likely to be maintained for a while, an OS update probably won’t kill it, I’ll never need to to worry about serial numbers or licensing it between my desktop and laptop, and it will update automatically when I update other App Store apps.
So I’m going to try PDFpen for a while. I’ve been eyeing it for years because it does a lot of very useful things, but I’ve never quite been pushed to get it for a particular need. But I think this is it.
I don’t know much about patents or the legal theory around them. But I do know about the practice and profession of developing software.
Like alcohol prohibition, patent law is based on myths and assumptions about what should be, not what is. Sometimes it works as intended, but it also has steep costs to society, and it might not be worth it — or, more likely, it might need to be scaled back.
Patents have a clear goal, as Dr. Drang quoted from the U.S. Constitution:
To promote the Progress of Science and useful Arts, by securing for limited Times to Authors and Inventors the exclusive Right to their respective Writings and Discoveries;
Excluding copyright (“Writings”), which I believe is a net positive, this implies that:
Science would not advance sufficiently without inventors being able to legally prohibit others from copying or using their discoveries.
The act of invention, not production or bringing to market, is where we want to place the most value as a society.
The value we place on the act of invention is higher than the cost imposed on the rest of society by not being able to use the invention freely.
In practice, I don’t believe that any of these apply to many patentable “inventions”. Software and business methods, in particular, are extremely problematic for that last assumption.
But there’s a bigger argument against software patents.
Look around the world of modern software. It expands and advances so quickly, and so much innovation is contributed by such small firms and authors, that very little software is patented.
And we’re fine.
Someone figures out a great new technique to use on a shopping site, they benefit immediately, then everyone else adopts it and they benefit, too.
I figured out lots of ways to detect “body” text for Instapaper’s text parser and patented none of them. Many others figured out the same metrics before and after I did and made similar text parsers. We all benefitted.
I invented many useful behaviors in the Instapaper bookmarklet. Many of those have been copied, too. And I bet I thought I “invented” something that someone else had already done years ago. Lots of people have done the same things as lots of other people in software without acquiring or wielding patents.
The entire software industry works like this, and the use of patents is very rare relative to all software that’s written. The market rewards applied innovation, but doesn’t try to artificially inhibit competition. It combines the best parts of capitalism, collaboration, and a vast public domain.
Our industry is booming, innovation is rapid and rampant, and everyone’s making a living. The world could benefit immensely if more industries could innovate as rapidly and significantly as the software industry. We’re doing great, almost entirely without using patents.
The best argument against software patents is that we don’t need them.
And I bet we’re not the only industry that’s better off without patents.
In this episode: what to expect at WWDC (and what to bring), thoughts on Xcode 4, the benefits of having an App-Store-apps-only default preference in a future Mac OS, Google’s API shutdowns, Twitter photo-hosting, and whether iOS development consultants need to expand to Android.
Paul Miller wrote a great review at This Is My Next that any potential Nook owner should read. But it doesn’t seem like he owns a Kindle or does a lot of e-ink reading, so I’m going to take a different slant: whether someone who wants an e-reader should choose the Nook Simple Touch over the Kindle 3, or whether Kindle 3 owners should consider switching to the Nook.
First, a disclaimer: I’ve only had the Nook for a day. But I can already tell you quite a lot about it, and generally speaking, it’s very similar to the Kindle 3.
Hardware
The Kindle 3 and Nook Simple Touch cost about the same, weigh about the same, feel about the same, and have the same-generation, same-resolution e-ink screen. (The weight and thickness are both technically different, but the difference isn’t meaningful during use.) The bezels are about the same color and thickness. They both even use the otherwise rare PMN Caecilia font by default, and both display pictures of famous dead authors as “screensavers” when they’re asleep.
Nook Simple Touch and Kindle 3 showing the same page, at the closest font settings I could get. From my trusty e-reader photography device: the flatbed scanner. Pardon the dust.
Barnes & Noble has copied so many facets of the Kindle that they clearly want consumers to think that this is a Kindle. They’re unquestionably trying to cause confusion in the market, presumably to increase their chances. I’m not a fan of this approach to competition; there’s enough potential differentiation that the runner-up needn’t outright copy the market leader so blatantly. (This is also the problem I have with the HP TouchPad’s hardware.) All parties, especially consumers, are better off when competing products move beyond knockoffs and become meaningful alternatives.
Despite a lot of blatant copying, B&N has innovated in a few major areas. The most obvious, and also the most significant, is the replacement of almost all hardware buttons with a touch screen, allowing the Nook to omit the entire keyboard “chin” that the Kindle needs.
E-readers don’t need a lot of keyboard input, so this makes sense: just give us an on-screen touch keyboard when we need to buy a book or enter a search term, so at all other times, we don’t need all of this wasted space at the bottom of the device.
Even though it rarely comes up in use, I found the Nook’s on-screen keyboard much faster and easier to type on than the Kindle’s physical keyboard. E-ink refreshes too slowly to make a lot of interfaces responsive enough to be usable, so I previously would have assumed that an on-screen keyboard wouldn’t work well, but I’m happily wrong about that. It’s nowhere near the responsiveness and quality of a modern smartphone touch-keyboard, but it’s the best I’ve seen on an e-reader. There’s no excuse for Amazon to keep the physical keyboard in the next Kindle.
Reading
Reading is very similar on both devices. If you’ve used a Kindle 3 already, nearly everything you like (or don’t like) about it will apply equally to the Nook.
The Nook’s reading screen.
B&N has optimized the e-ink update method to not require the full-screen “blink” that the Kindle does on every page-turn, but the promo videos are misleading: the Nook does fully blink, but only on every sixth page-turn. Even on non-blinking page-turns, the overall page-turning speed is about the same as the Kindle’s.
This isn’t a generational leap forward: it’s the same screen giving the same overall reading experience as the Kindle.
Text controls.
Both readers have similar text controls. The Nook offers more fonts, while the Kindle offers rotation and one more size option.
The Nook’s margins can’t be set to match the Kindle’s: they’re either much wider or much narrower. My screenshots are all at the widest of the three settings, because the default middle value is too thick and puts too few words on each line.
Maybe it’s because I’m accustomed to Caecilia, but I didn’t find the Nook’s other fonts nearly as readable: Gill Sans and Helvetica work moderately well, Trebuchet and Amasis render poorly, and I find Malabar’s thickness uncomfortable.
The Kindle’s rendering is slightly more readable, with the Nook’s too often aligning on half-pixel boundaries, resulting in thin gray strokes. This is least noticeable with Caecilia but is problematic with the thinner fonts, especially Gill Sans and Trebuchet.
The Nook aggressively hyphenates, which I found distracting. As far as I can tell, the Kindle doesn’t hyphenate. Both readers’ inconsistency between ragged-right and justified, with no option to change it, is annoying.
I’ve colored and labeled the tap zones on the main screen as it displays the reading menu.
Page-turning is easiest by tapping the vertical margins. It responds reasonably quickly and doesn’t “click” to annoy those around you.
The left and right bezels contain rubber-covered page-turning buttons if you choose to use them instead, but they’re poorly implemented (although very quiet). They require much more pressure than the Kindle’s page-turning buttons: I need to bend my thumb inward to apply enough pressure, whereas on the Kindle, I can just rest it on top of the button and gently press down. Page-turning by touching the screen is far more comfortable. Regardless of page-turning method, I need to fundamentally hold the Nook and Kindle differently, and I haven’t yet found my ideal hold for the Nook.
The buttons also map strangely in the interface: by default, the top pair is “next page” and the bottom is “previous page”. But when scrolling a list or table of contents, they map like a scrollbar: the bottom is “next page” and the top is “previous page”.
It’s easier and better to ignore the side buttons and just touch the screen for everything.
The touch screen
The touch-screen navigation, overall, is great.
The Nook embarrasses the Kindle for everything that Kindle users need to use the 5-way buttons for: menu navigation, book selection, table-of-contents navigation (especially in periodicals), and text selection for highlights or definitions.
Browsing The New York Times.
Many touch targets need to be adjusted. For instance, to open an article in this New York Times section, you must tap the headline text — the entire list item is not tappable. (And tapping it near the margins will “page” the list.)
The more general problem is that many touch targets are unintuitive. The user is often left to guess where to touch to perform a desired action, and it’s easy to guess wrong.
But I still greatly prefer the Nook’s sometimes-confusing touch screen to the Kindle’s wall of tiny buttons, especially when attempting any sort of navigation.
A few other small notes on the device itself:
The menus and interface screens are all better-designed, visually, than the Kindle’s. The Nook’s interface looks clean and modern, with excellent use of whitespace and graphics, while the Kindle’s interface is utilitarian and text-heavy.
To wake the Nook from sleep, you need to push the home button and perform a slide-to-unlock gesture. The iPhone can pull this off because it’s much more responsive. But every time I use the Nook, the slide-to-unlock just slows me down and annoys me.
The Nook has no “Back” button, impeding section-jumping and footnote navigation.
The Nook can’t follow web links, since there’s no browser. The Kindle’s browser is awful, but it’s there if you need it. This isn’t a problem with most novels, but it’s relevant for many modern magazines and newspapers that are embedding links, and any content that originated as web pages (like Instapaper).
Any object registers as a “touch” on the screen, including clothing and blankets.
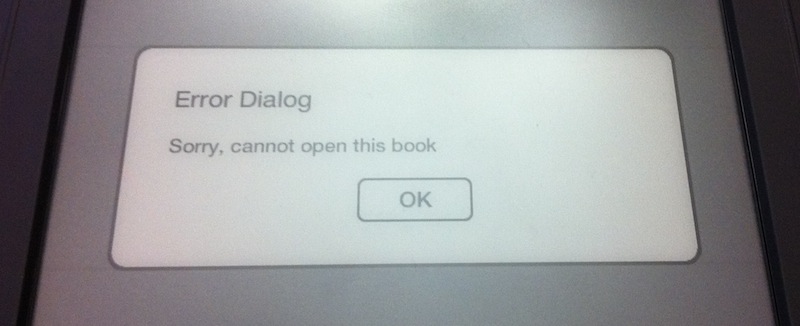
The software is still buggy, often becoming unresponsive for 10 seconds or more. I hit this unresponsiveness followed by a meaningless error dialog after entering my billing address during the initial setup. And once today, the touch screen completely stopped working until a reboot.
B&N put a lot of effort into social sharing features. I can highlight an interesting quote and easily send it to Twitter or Facebook… but I can’t email it to myself (or anyone else). Email is the biggest sharing network in the world.
Like the Kindle 3, my favorite case for the Nook is a nearly weightless and effectively free DVD bubble mailer with the excess length cut off the top.
Overall, I’d classify this Nook as being a generational equivalent to the Kindle 3, but the Kindle 3 is nearly a year old. Launching an equivalent competitor to it today is like launching an iPad 1 competitor in February 2011.
I’d be much more impressed with this Nook had it launched last summer, and it worries me that B&N is only now using the same e-ink screen generation that Amazon had then. (What will the next Kindle use?)
But I like it. And I love the touch interface.
If the review ended here, I’d probably conclude that the Nook is a great alternative to the Kindle for nearly all potential buyers. But these e-readers aren’t self-contained — they’re primarily vending machines for two very different publishing ecosystems.
In a heavily ecosystem-dependent category like this, one good hardware release isn’t enough.
The supporting ecosystem
The Kindle wins here, hands down. Amazon’s store has noticeably more books, newspapers, and magazines that people are likely to want. Many titles I’ve searched for aren’t available for the Nook but are available on the Kindle, and I haven’t yet found a case where the opposite is true.
Furthermore, Amazon’s DRM really hurts experimentation: I can’t transfer Kindle books to the Nook or vice versa, so now that I’ve purchased Kindle books, I’m strongly encouraged to stay with the Kindle device family.
While this will matter to very few Nook owners, I can’t use Instapaper or any other online service to send web content to the Nook: there’s no document-delivery mechanism like Amazon’s email gateway, and no web browser to download files directly. The only way to get non-B&N content onto the Nook, as far as I can tell, is to transfer it via USB or a micro-SD card.
If you own an iPad in addition to an e-reader and want to run the respective Nook or Kindle iPad apps, you’re much better off with the Kindle. The Nook iPad app works, but it’s mediocre, while the Kindle app is excellent.
What this means for the Kindle
The Nook Simple Touch isn’t going to convert a lot of Kindle fans. Amazon’s ecosystem is going to keep a lot of people in.
My ideal e-reader would be the Nook hardware and interface, but backed by the Kindle’s ecosystem and services. It’s easier for Amazon to achieve Nook-like hardware design than for B&N to achieve a Kindle-like ecosystem, so it’s much more likely that the next Kindle will be a better fit than the current (or next) Nook.
I hope the competition lights a fire under Amazon to improve the Kindle, but the strength of Amazon’s ecosystem over B&N is going to keep me there for the foreseeable future regardless, and I’d still tell a prospective new customer to choose the Kindle.
But if that new customer isn’t in a rush, I’d strongly suggest waiting to see how Amazon responds with the next Kindle.
Tweetmarks is a web service for setting and getting the “last read” tweet for a given Twitter user. It can be used to “sync” the reading position between multiple Twitter clients and platforms.
I’d love if many Twitter clients integrated this.
Unfortunately, I doubt that Twitter’s official Mac and iOS apps will. Twitter has decided, for whatever reason, not to do this to date. I heard a while back that this was because they want people to just read what’s there now, like a river of news, not to try to “keep up” with a potentially insurmountable timeline. They didn’t want to encourage features like this that would allow someone to know how far “behind” they are, because that could cause guilt and feelings of information overload, which could discourage usage. (For many of the same reasons, I don’t display “unread count” badges anywhere on Instapaper.)
But the official Twitter apps all have those blue “unread” dots, which function very poorly without unread-status syncing. Each app is great if it’s the only one you use, but if you try to use, say, the iPhone and iPad clients, this problem can annoy you every day.
Maybe Twitter will add unread-status sync to the API someday, but I doubt it.
And as long as Twitter doesn’t have an API for it, widespread Tweetmarks support in apps is badly needed for anyone who uses multiple Twitter clients. So if you make a Twitter client, please add Tweetmarks support.
The ability to run Mac OS X apps on the iPad, with full access to the file system, peripherals, etc., would make the iPad worse, not better. The iPad succeeds because it has eliminated complexity, not because it has covered up the complexity of the Mac with a touch-based “shell”. iOS’s lack of backward compatibility with any existing software means that all apps for iOS are written specifically for iOS.
It’s the lesson that so many hardware and platform vendors can’t seem to learn: the pretty skin isn’t why people like Apple products, and applying a pretty skin over your products won’t make them compete better with Apple’s.
Steve Jobs said it best: “[Design is] not just what it looks like and feels like. Design is how it works.”
Before today, I knew that a reading-list feature similar to Instapaper’s core bookmark-saving purpose was being added to Safari in Lion, and wrote a big blog post about its potential impact on Instapaper.
I speculated that they wouldn’t add it to iOS in the first version, but probably would in the future. That was incorrect: they actually are adding it in iOS 5, coming this fall. Only the timing is news today, not these features’ existence.
The conclusion I drew at the time still stands:
My biggest challenge isn’t winning over converts from my competitors: it’s explaining what Instapaper does and convincing people that they actually need it. Once they “get it”, they love it, but explaining its value in one quick, easy-to-understand, general-audience sentence is more difficult than you might imagine.
If Apple gets a bunch of Safari users — the browser that works best with Instapaper — to get into a “read later” workflow and see the value in such features, those users are prime potential Instapaper customers. And it gives me an easier way to explain it to them: “It’s like Safari’s Reading List, but better, in these ways.”
Today, fewer than 1% of iPhone, iPad, and iPod Touch owners are Instapaper customers, despite Instapaper spending a lot of time (including today) at the #1-paid-app spot in the App Store’s News category for both iPhone and iPad. The potential market is massive, but most people don’t know that they need it yet.
When iOS 5 and Lion ship, Apple will show a much larger percentage of iOS-device owners that saving web pages to read later is a useful workflow and can dramatically improve the way they read.
If Reading List gets widely adopted and millions of people start saving pages for later reading, a portion of those people will be interested in upgrading to a dedicated, deluxe app and service to serve their needs better. And they’ll quickly find Instapaper in the App Store.
So I’m tentatively optimistic. Our world changes quickly, especially on the cutting edge, and I really don’t know what’s going to happen. (Nobody does.) But the more potential scenarios I consider, the more likely it seems that Safari’s Reading List is either going to have no noticeable effect on Instapaper, or it will improve sales dramatically. Time will tell.
(I don’t know where to start with everything that happened and was unveiled in the last week, so I’ll pick randomly and start here.)
As much as I dislike feature-checklist comparisons, many people base their buying decisions on them, either by choice or by corporate-policy decree.
Since the iPhone’s release in 2007, many prospective buyers have declined to choose the iPhone because of a real or perceived shortcoming in its feature checklist.1
Every time iOS or the iPhone is updated, Apple picks away at that list. They started with the big ones: purchase price, 3G, GPS, copy and paste, advanced security features, Exchange, multitasking. More recently, they added Verizon support, and it wouldn’t surprise me to see them quietly hit Sprint and T-Mobile in the future, picking away at that list even further.
With iOS 5, they’ve hit tons of relatively minor shortcomings. Notifications. Quick camera access and a hardware shutter button. Wireless sync and backup. They’ve even added a preference to have the camera-flash LED blink on new notifications, supposedly as an accessibility feature, but also conveniently to appeal to BlackBerry owners addicted to that blinking LED.
Apple has steamrolled over almost every meaningful advantage that competitors have. And they’re not stopping.
There are lots of hardware preferences that I suspect will always be reasons why some people wouldn’t choose an iPhone, such as the demand for hardware keyboards, removable batteries, different form factors, or significantly cheaper prices.
Very few major items are still on that list that I think Apple would actually change. But it’s usually unwise to say that Apple will “never” do something. And it looks like they’re willing to do quite a lot to get more iPhone customers, even if a change require temporarily suspending some of their usual priorities.
When speculating on what Apple will or won’t do, a change that gets them more iPhone customers is probably worth considering even if you think they’d “never” do it. iPhone customer acquisition is a higher priority than almost everything else.
I’ve intentionally ignored the iPad in this post because the reasons people choose iPads are completely different, and very few people are buying iPad competitors as a result of the iPad not satisfying their criteria. ↩︎
A special episode of my podcast with Dan Benjamin, recorded from WWDC last week, to discuss Mac OS X Lion, iOS 5, iCloud, iMessage, Reading List, Instapaper, and more.
David Barnard of App Cubby reconsiders possible alternate explanations of some of Twitter’s recent PR statements:
Some of us are trying to take a more optimistic view of things while others have been so badly burned it’s hard to give Twitter another chance. My hope is that in the months preceding the launch of iOS 5, Twitter will do a better job communicating with developers and better explain some of its prior comments.
There’s definitely more to the story than Twitter lets on publicly. With almost any PR statement, analytical readers must try to distinguish what’s literally said from the real story and the reasons behind it.
In most cases, there are very good reasons why a company the size of Twitter does or says something, but for other very good reasons, they usually can’t say exactly why.
Daniel Amitay’s iPhone app had a configurable 4-digit numeric lock screen, and he anonymously aggregated the passcodes that people set in his app for analysis:
Because Big Brother’s passcode setup screen and lock screen are nearly identical to those of the actual iPhone passcode lock, I figured that the collected information would closely correlate with actual iPhone passcodes.
This potentially shady data collection got him booted from the App Store (at least temporarily), but the data’s interesting.
Reported by the awesome MG Siegler on that website he writes for:
As we understand it, Project Spartan is the codename for a new platform Facebook is on verge of launching. It’s entirely HTML5-based and the aim is to reach some 100 million users in a key place: mobile. More specifically, the initial target is both surprising and awesome: mobile Safari. […]
Facebook will never admit this, but those familiar with the project believe the intention is very clear: to use Apple’s own devices against them to break the stranglehold they have on mobile app distribution.
Just what we need: another app store (™?).
But with Facebook’s immense scale, this is probably going to be interesting, at least.
I listened to every episode of the old Stack Overflow podcast when it started back in 2008, as I was walking to work to build Tumblr. So it was a great honor to be on the show, and I had a lot of fun doing it.
Also, I love arguing with Jeff Atwood. We have very similar personalities, we both “know” we’re right a bit too often, and we disagree on nearly everything. Normal people in such a situation would probably kill each other, but I love it.
Would everyone have praised Apple for its “noble experiment” if the $500 iPad had been too big and heavy, felt like it was worth only $180, and was “a 3.3-pound paperweight” when offline? Fuck that. This is the big leagues. There is no credit for trying.
— John Gruber on David Pogue’s suggestion that we “praise Google for its noble experiment” that resulted in the abysmal Chromebook.
The Galaxy Tab 10.1 easily has the best hardware of any Android tablet on the market today. Samsung has really outdone itself—the Tab 10.1’s svelte profile and impressively light weight (it weighs less than an iPad and has more RAM) are sure to attract the attention of consumers.
Really? Will a lot of customers notice the 2% thickness difference or the 6% weight savings over an iPad 2? I guess it must be the RAM they’re clamoring for, since that’s a hotly debated spec among iPad buyers.
Hardware excellence isn’t the only measure of a good tablet, however; software is arguably just as important—if not more so—on such a personal device.
Google has moved Honeycomb forward with Android 3.1 and has thankfully fixed the stability problems, but that’s still not enough. Honeycomb’s barren third-party application landscape really hobbles the Tab 10.1 and other Android tablets.
Translation: Android tablets have managed to copy the iPad’s hardware well enough — the easy part — but have failed to provide good software and significant third-party app choice — the hard part.
So, with similar hardware with similar capabilities selling at similar prices, why should someone choose an Android tablet over an iPad?
The main users who will find the Tab 10.1 appealing are Android enthusiasts who like the platform’s flexibility, are tightly bound to Google’s Web service ecosystem, and are comfortable using Android phone applications on a 10.1-inch screen.
“Only die-hard Android fans should buy this, and even most of them won’t enjoy it.”
The Tab 10.1 is also a good choice for third-party Android developers looking for real-world hardware on which to test and develop their applications.
(I’ll come back to this.)
The 16:10 aspect ratio and dual speakers also make the Tab 10.1 a reasonable choice for users who watch a lot of mobile video. One problem, however, is limited content; no compatible Netflix or Crackle applications exist for the Tab 10.1—just Google’s nascent video rental service and whatever content is available via Flash in the browser.
“The Tab is a reasonable choice for people who watch a lot of video, as long as it’s all pirated, because there’s almost no legal content available.”
The Tab 10.1 is a much more credible product than the Xoom, but it’s not quite competitive with the iPad.
Is it safe to assume that “it’s not quite competitive with the iPad” means “almost nobody should choose this over the iPad”?
If Google wants to compete, it still needs to build a vibrant third-party application ecosystem in order to make Android tablets a good option for regular users.
This is a classic chicken-and-egg problem. Google, and any other tablet makers, needn’t be so concerned about attracting developers. Developers come, generally, when at least two of these three criteria are met:
Developers themselves use and love the platform’s products.
The platform has a large installed base.
Developers can make decent money on the platform.
Different types of developers, and therefore different types of apps, show up depending on which criteria are met. Windows has lost a lot of ground on the first for quite some time. Mac OS struggled with the second for most of its history. Android phones have had a lot of trouble achieving the third. And, to date, Android tablets have failed to meet any of them.
The iPhone hit the first two immediately upon its launch, before developers could even make apps for it. We practically beat the doors down. Apple didn’t need to do anything to encourage us — in fact, they had to keep us back for the first year until they were ready for the onslaught, at which point we realized that the third criterion was satisfied.
The iPad hit all three immediately, helped in part by the iPhone’s success, and once again, developers rushed to it. No respectable reviews ever complained that there were too few iPad apps, or that it would be a useful product “soon”.
The gadget reviewers seem to believe that it’s only a matter of time before these theoretical developers rush into the Android-tablet market with tons of high-quality apps. But time isn’t the problem. If these tablets continue (not) selling at their current pace, the reviewers (and the unfortunate few early adopters who bought these things) will be waiting forever.
Developers will rush to Android tablets once a lot of people are buying Android tablets. But hardly anyone will buy them if there’s too little compelling software available.
So there must be a very good reason why someone would choose any given Android tablet over an iPad, and that reason can’t be the available apps.
This, not how closely a manufacturer can mimic the iPad’s hardware, is what reviewers should be asking about each new tablet: Why would a significant number of buyers choose this instead of an iPad?
Or, more generally: What will cause enough people to buy this that developers will beat down the door to make great apps for it?
I’m still waiting for any iPad “competitors” to give us a good answer.
In this week’s podcast episode, Dan and I revisited app-compatibility decisions and Twitter’s API PR, then discussed rising bars sinking all boats (or something like that), iCloud’s usefulness to web services, keeping your competitors close, and the incentives of low app pricing.
In the first version of my post from this morning, I wrote that the Ars Technica review of the Galaxy Tab 10.1 “exemplifies the softball ‘please keep sending us gadgets’ review so prevalent recently.”
This was a much more serious accusation than I intended: it implied fraud and a lack of journalistic integrity, which understandably is a horrible thing to accuse a journalist of, so I deleted that phrase. I sincerely apologize to Ars Technica and the article’s author, Ryan Paul, for that accusation.
What I intended to point out was the tendency of tech reviews to give too much credit for trying. Too many of the mediocre-gadget reviews I see by otherwise great sites seem like they’re stretching to balance the “pros” and “cons” lists with minutia and equivocation.
They rarely ever say anything blunt and honest, such as “Very few people should buy this.”
And they often fail to address the big-picture questions at all, such as “What will make this sell in enough quantity that we’ll still care about it in three months?”
That’s what I meant, but that’s not what I said, and I’m sorry. It’s easy to forget, sometimes, that there are people on the other end of what I write.
Seems a few months too soon for the Mac Pro. Apple doesn’t just pull new Macs out of thin air when they feel like it: they usually follow Intel’s roadmap closely, especially for the Xeon-based Mac Pro.
What’s happening in the Xeon line in July or August to motivate a Mac Pro update? As far as I can tell, nothing. The single-socket Xeon was recently updated to Sandy Bridge with the very good E3 line, but the dual-socket E5 line isn’t due out until the fourth quarter.
So, in descending order of likelihood: either this rumor’s timeline is wrong, Apple’s getting very early access to the Xeon E5, or the next Mac Pro isn’t offering any dual-socket models at launch.
(I can’t speculate on the Mac Mini on this basis, since it rarely uses a brand new CPU and usually is pulled out of thin air when Apple feels like it.)
James Fallows on the rumored truth behind the Google Translate API shutdown:
Google is dropping an automatic-translation tool, because overuse by spam-bloggers is flooding the internet with sloppily translated text, which in turn is making computerized translation even sloppier.
If true, this is intriguing. The bigger question, then, might be why Google isn’t doing more to attempt to distinguish autogenerated pages from “real” content. It’s a very difficult problem to solve, and it might not even be possible. But Google has both the biggest need for such a solution and the best resources with which to develop and maintain it.
Terminology is by far my favorite dictionary app for many reasons. It’s not just a dictionary — it’s also a thesaurus, with the functions nicely integrated into a great interface.
It integrates perfectly with Instapaper: install both, and Instapaper’s dictionary popovers will offer a link to look up any word in Terminology. Tap that link and Terminology will open with that word’s definition, offering a convenient button to switch back to Instapaper and continue reading.
Seems like the bill is mostly about how the USPTO is funded, but this part is a significant, fundamental change:
The bill generally updates the process for challenging patents and would change the patent system to one that awards a patent to the first inventor to file a specific claim.
Currently, the first person to invent something has patent priority, whether or not he is the first to file an application.
I’m not a lawyer and have only a surface-level understanding of this, but isn’t this a monumentally bad idea that will only make the U.S. patent system even more dysfunctional, more favorable to trolls and bulk patent filers, and more crippling to innovation by anyone but the largest companies capable of filing patents constantly?
Remember Kind of Bloop, the chiptune tribute to Miles Davis’ Kind of Blue that I produced? I went out of my way to make sure the entire project was above board, licensing all the cover songs from Miles Davis’s publisher and giving the total profits from the Kickstarter fundraiser to the five musicians that participated.
But there was one thing I never thought would be an issue: the cover art.
He got screwed by dick Jay Maisel, the insanely rich photographer of the original album’s cover art. Baio had to settle for $32,500, a sum that Maisel probably won’t even notice.
It breaks my heart that a project I did for fun, on the side, and out of pure love and dedication to the source material ended up costing me so much — emotionally and financially. For me, the chilling effect is palpably real. I’ve felt irrationally skittish about publishing almost anything since this happened. But the right to discuss the case publicly was one concession I demanded, and I felt obligated to use it. I wish more people did the same — maybe we wouldn’t all feel so alone.
Baio is yet another victim of the United States’ dysfunctional legal procedures surrounding intellectual-property laws, which ensure that nearly any barely-credible threat can extract a settlement from its target, even if it would never hold up in court, since only the extremely rich can afford to actually defend themselves in court.
In this week’s podcast, Dan and I discussed the FBI’s raid at DigitalOne, database backups, lossless audio compression algorithms, and the content ecosystems that tablets and e-readers depend on.
My take on bcrypt, adapted1 from phpass, since I learned last week that salted SHA-1 hashes aren’t secure enough anymore for password validation.
I’d love to get input from any security experts out there on whether this approach — essentially, only the CRYPT_BLOWFISH part of phpass — is sufficiently secure before I deploy it.
You might be wondering why I didn’t just use phpass. Most of its code is only necessary for legacy versions of PHP prior to 5.3, and I’d rather not have more code (and more potential vulnerabilities or shortcomings) than I need. I also wanted to modernize the code for PHP 5’s (and my own) conventions. ↩︎
A minor note from Apple’s PR FAQ to address Final Cut Pro X complaints:
Can I purchase a volume license?
Final Cut Pro X, Motion 5, and Compressor 4 Commercial and Education Volume Licensing will be available soon via the Apple Online Store for quantities of 20 or more. After purchasing, customers will receive redemption codes they can use to download the applications from the Mac App Store.
That’s interesting. Presumably they’re going to issue more than 50 redemption codes for each release. This sort of flexibility sure would be beneficial to other developers with products in the App Store.
Breaking news: a huge advertising company would like you to give them as much of your personal information as possible and encourages you to use their services more frequently, for more reasons, and for longer durations each time so they can show you more ads and make more money from the advertisers.
It’s not difficult for a company of Google’s size to make a social network. The challenge is getting enough people to use it, and quickly enough, that the early adopters will stick around after the first few days and start habitually using it.
This is an extremely high barrier to entry, even for Google. As with most social phenomena, social-network success tends to happen more organically and unpredictably than anyone is able to artificially create by throwing money at it.
Successful social services at this scale also need constant attention, rapid improvements, and nearly flawless product direction — skills that Google hasn’t been able to consistently deliver to many of their products.
The network effect is extremely high in social networks. It’s absolutely a boil-the-ocean problem. For Google+ to be useful to you, most of your “friends” (in some context) need to be using it on a regular basis. And most people won’t use more than one social network regularly.
To get widespread adoption, therefore, this needs to take a lot of users away from Facebook, and quickly. Google+’s specific features are far less relevant until after (and if) it gets widespread use and competes strongly with Facebook.
So instead of analyzing the specific features, let’s ask that big question: Will a lot of people use Google+ instead of Facebook?
I don’t know the answer. I’m terrible at predicting what will and won’t be successful, especially socially. Navigating the demo site was frustrating and confusing for me, and it seems like more effort was spent making Google’s staff happy than considering its clarity and usefulness to users — a common complaint I have with Google’s products.
But I don’t have access to the actual service, and initial reviews from people in the private beta are positive.
Like most people, I’ll join Google+ when I’m motivated to join by social factors. Let’s see if that happens, when, why, and for how many people.






{kind=link}
{kind=link}